- Устройство изменения голоса в реальном времени на Ардуино
- Комплектующие
- Проект
- Схема устройства
- Код проекта
- Схемы имитаторов звуковых эффектов, изменение голоса
- Схемы имитаторов звуковых эффектов, изменение голоса
- Схема приставки
- Второй вариант приставки
- Преобразователя напряжение-ширина импульсов
- Преобразователь голоса своими руками
Устройство изменения голоса в реальном времени на Ардуино
Создадим устройство на основе шилда Audio Hacker и платы Arduino, которое будет изменять голос в реальном времени.
Чтобы сразу понять как это работает — лучше всего посмотреть видео ниже. За проект огромное спасибо ребятам из «nootropic design».
Комплектующие
Для этого устройства нам понадобится немного деталей:
- Arduino UNO или Genuino UNO × 1
- Audio Hacker shield × 1
- Поворотный потенциометр (универсальный) × 1
Проект
Простой проект с использованием шилда Audio Hacker для плат Arduino от компании»nootropic design». Это речевой чейнджер (от англ. — замена) в реальном времени, который является усовершенствованием исходного примера, который предоставлен в библиотеке Audio Hacker.
Мы используем технику, называемую гранулярным синтезом, чтобы изменить высоту ввода. Гранулярный синтез довольно сложен, но он включает в себя разделение семпла на маленькие фрагменты, называемые «зернами».
Гранулярный синтез (англ. Granular synthesis) — последовательная генерация звуковых гранул. Каждая гранула — это ультракороткая частица звука длиной в 10—100 миллисекунд. Звук получается в результате быстрого взаимодействия частоты повторения и частотных составляющих гранул, который далее может быть отфильтрован и сформирован огибающей методами вычитающего синтеза. Гранулами часто управляет Клеточный Автомат, который производит псевдослучайные последовательности. Гранулярный синтез очень сложен в управлении и даёт совершенно неожиданные результаты.
Одним из первых реализаций гранулярного синтеза была в программе Ross Bencina AudioMulch в виде эффекта, а уже потом появилась в виде синтезатора в Reason.
Из наиболее известных программных инструментов, применяющих гранулярный синтез, можно назвать Аbsynth, а из эффектов — Glitch. В аппаратном решении гранулярный синтез можно встретить в рабочей станции Kyma, а также в приборах обработки звука Eventide.
Теория гранулярного синтеза была разработана Дэннисом Габором.
При воспроизведении семпла, если мы хотим увеличить высоту тона, мы воспроизводим «зерно» с более высокой скоростью, но мы воспроизводим его снова и снова до тех пор, пока это не займет столько же времени, сколько и «зерно», воспроизводимое на исходной скорости. Аналогично, чтобы снизить высоту, мы воспроизводим каждое «зерно» с более медленной скоростью, но переходим к следующему «зерну раньше», чтобы общая длительность сэмпла была одинаковой.
Этот речевой чейнджер в реальном времени только снижает высоту звука. Повышение высоты звука потребует задержки для записи чего-либо и более быстрого воспроизведения фрагментов. Понижение высоты звука достигается записью входа и одновременным его замедленным воспроизведением. То есть «воспроизводящая головка» движется медленнее, чем «записывающая головка». Иногда воспроизводящая головка должна пропускать некоторые входные данные и догонять записывающую головку. Таким образом, воспроизведение занимает столько же времени как запись, что создает ощущение реального времени.
Схема устройства
Схема нашего устройства представлена на изображении ниже. Нажмите для увеличения.

Код проекта
Примеры и основной код устройства в архиве ниже, а также на GitHub странице автора. Вы можете загрузить библиотеку в IDE Arduino с помощью:
File -> Examples -> Audio Hacker -> RealtimeVoiceChanger
На этом всё. Надеемся, что вы будете использовать это устройство только в законных целях.
Источник
Схемы имитаторов звуковых эффектов, изменение голоса
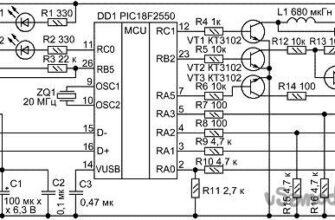
Схема (рис. 5.73) предназначена для работы с любым источником звукового сигнала и позволяет изменить спектр на выходе относительно входного. Например, из обычной разговорной речи сделать “компьютерный голос». Достигается это за счет модуляции исходного сигнала прямоугольными импульсами, которые формирует генератор на микросхеме DA1 (рабочая частота у него выбрана около 10 Гц).
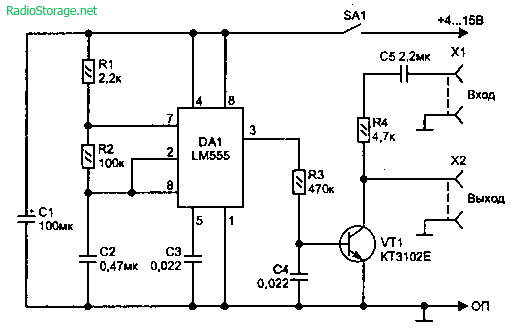
Рис. 5.73. Схема приставки для имитации “компьютерного” голоса
Возникающие при этом искажения создают новые частотные составляющие в спектре исходного сигнала, которые и меняют тембр звука, например голоса, делая его менее похожим на оригинал. Для получения нужного спектра может потребоваться регулировка элементов R3 и R2. Транзистор используется в качестве управляемого напряжением резистора и образует вместе с R4 управляемый напряжением аттенюатор.
Еще одна схема для изменения спектра сигнала показана на рис. 5.74 [Л40]. В ней звуковой сигнал модулируется с частотой 50-90 Гц (частота изменяется резистором R2), вырабатываемой микросхемой DA1. Чтобы не было сильных искажений и ухудшения разборчивости, входной сигнал не должен превышать уровень в 150 мВ и поступать от источника с низким выходным сопротивлением, например, от электродинамического микрофона. Выходной сигнал подается на любой внешний усилитель. При этом во многих случаях можно не устанавливать конденсаторы С4-С5 (если в звуковом сигнале нет постоянной составляющей).
Для создания некоторых устройств (стабилизации напряжения или скорости вращения электромотора, автоматического зарядного устройства и др.) может потребоваться преобразователь управляющего входного напряжения в ширину выходных импульсов. Вариант схемы такого узла приведен на рис. 5.75 [Л46], она обеспечивает точность преобразования не хуже 1 %.

Рис. 5.74. Второй вариант приставки для создания звуковых эффектов
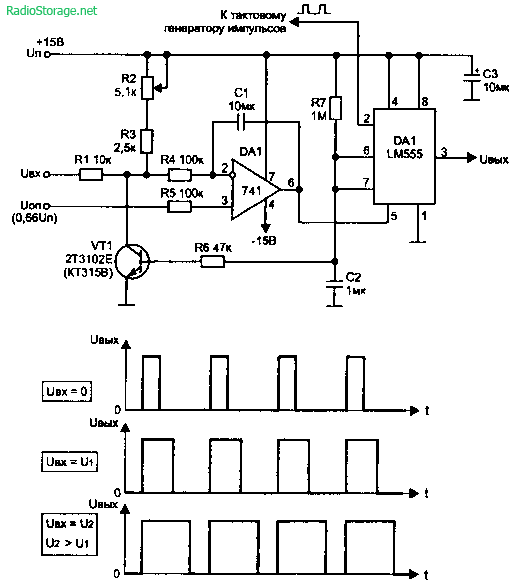
Рис. 5.75. Схема преобразователя напряжение-ширина импульсов и диаграммы, поясняющие работу
Микросхема DA1 имеет отечественный аналог К140УД7 и работает в качестве интегратора разности напряжений Uвх и Uon, а на таймере DA2 собран одновибратор с запуском от внешнего тактового генератора. Резистор R2 служит для установки нужной минимальной ширины импульсов.
Литература: Радиолюбителям: полезные схемы, Книга 5. Шелестов И.П.
Источник
Схемы имитаторов звуковых эффектов, изменение голоса
Приведены принципиальнаые схемы приставок для обработки голоса, получения искажения по типу «компьютерный голос». Устройства будут полезны для озвучивания разных событий с использованием звуковых эффектов.
Схема приставки
Схема на рисунке 1 предназначена для работы с любым источником звукового сигнала и позволяет изменить спектр на выходе относительно входного. Например, из обычной разговорной речи сделать “компьютерный голос». Достигается это за счет модуляции исходного сигнала прямоугольными импульсами, которые формирует генератор на микросхеме DA1 (рабочая частота у него выбрана около 10 Гц).

Рис. 1. Схема приставки для имитации компьютерного голоса.
Возникающие при этом искажения создают новые частотные составляющие в спектре исходного сигнала, которые и меняют тембр звука, например голоса, делая его менее похожим на оригинал.
Для получения нужного спектра может потребоваться регулировка элементов R3 и R2. Транзистор используется в качестве управляемого напряжением резистора и образует вместе с R4 управляемый напряжением аттенюатор.
Второй вариант приставки
Еще одна схема для изменения спектра сигнала показана на рисунке 2. В ней звуковой сигнал модулируется с частотой 50-90 Гц (частота изменяется резистором R2), вырабатываемой микросхемой DA1.

Рис. 2. Второй вариант приставки для создания звуковых эффектов.
Чтобы не было сильных искажений и ухудшения разборчивости, входной сигнал не должен превышать уровень в 150 мВ и поступать от источника с низким выходным сопротивлением, например, от электродинамического микрофона. Выходной сигнал подается на любой внешний усилитель. При этом во многих случаях можно не устанавливать конденсаторы С4-С5 (если в звуковом сигнале нет постоянной составляющей).
Преобразователя напряжение-ширина импульсов
Для создания некоторых устройств (стабилизации напряжения или скорости вращения электромотора, автоматического зарядного устройства и др.) может потребоваться преобразователь управляющего входного напряжения в ширину выходных импульсов. Вариант схемы такого узла приведен на рисунке 3, она обеспечивает точность преобразования не хуже 1 %.

Рис. 3. Схема преобразователя напряжение-ширина импульсов и диаграммы, поясняющие работу.
Микросхема DA1 имеет отечественный аналог К140УД7 и работает в качестве интегратора разности напряжений Uвх и Uon, а на таймере DA2 собран одновибратор с запуском от внешнего тактового генератора. Резистор R2 служит для установки нужной минимальной ширины импульсов.
Литература: Радиолюбителям: полезные схемы, Книга 5. Шелестов И.П.
Источник
Преобразователь голоса своими руками
Прежде всего — С НОВЫМ ГОДОМ!
Срочно нужно выбрать тему для дипломной работы.
В связи с этим хотел бы обратиться к вам. Узнать ваше мнение.
1. Схема для изменения голоса.
Суть:
Все вы знаете МАКСИМА ГАЛКИНА.
Он пародирует знаминитостей.
В принципе у каждого человека есть свой тембр голоса, некая постоянная частота его говора.
Что если эту постоянную частоту распознать и заменять её на другую, какую вы захотите. Электронно естестно.
Вы берёте микрофон — выбираете чим голосом будете говорить и говорите в микрофон своим голосом а спец схема преобразовывает вашу тональность в другую.
Ваше мнение, заранее спасибо.
Последний раз редактировалось Радиогубитель! Сб дек 30, 2006 21:45:53, всего редактировалось 1 раз.
| Реклама | ||
| | ||
Мышонок  | | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Карма: 6 |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||