- Делаем парсеры контента своими руками
- Учимся писать парсер сайта своими руками
- Парсинг любого сайта «для чайников»: ни строчки программного кода
- Что такое парсинг и зачем он нужен
- ПО для парсинга
- Пример 1. Как спарсить цену
- Куда вписывать XPath-запрос
- Как подобрать страницы для парсинга
- Пример 2. Как спарсить фотографии
- Ищем свойства картинок
- Пример 3. Как спарсить характеристики товаров
- Изучаем характеристики
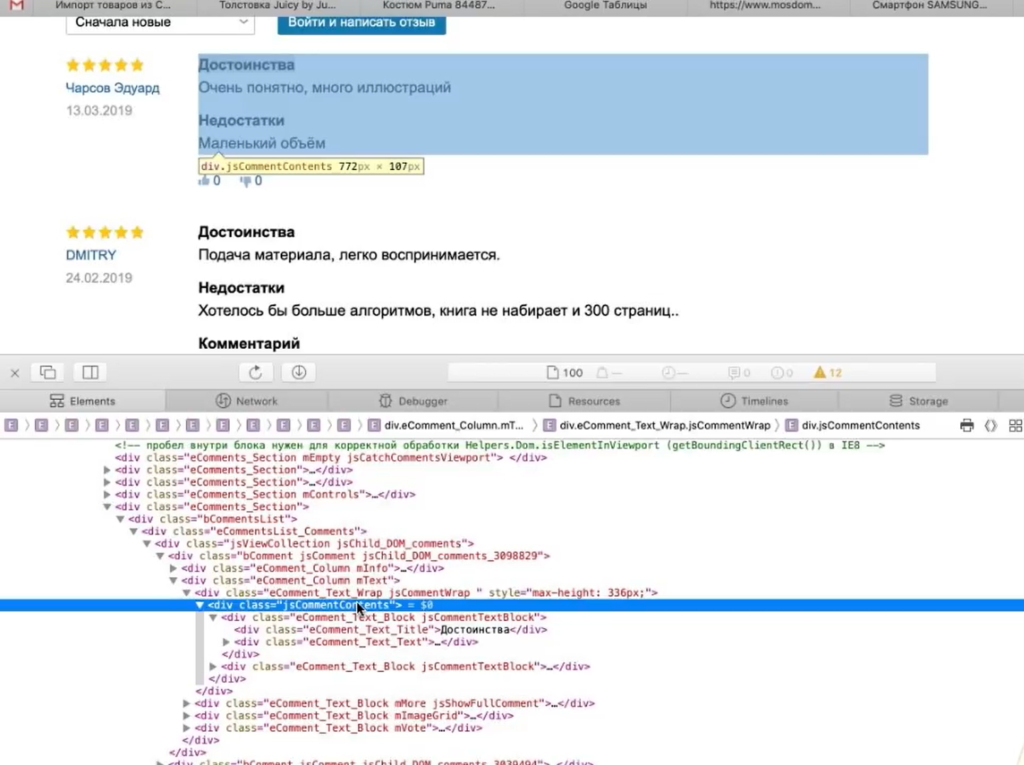
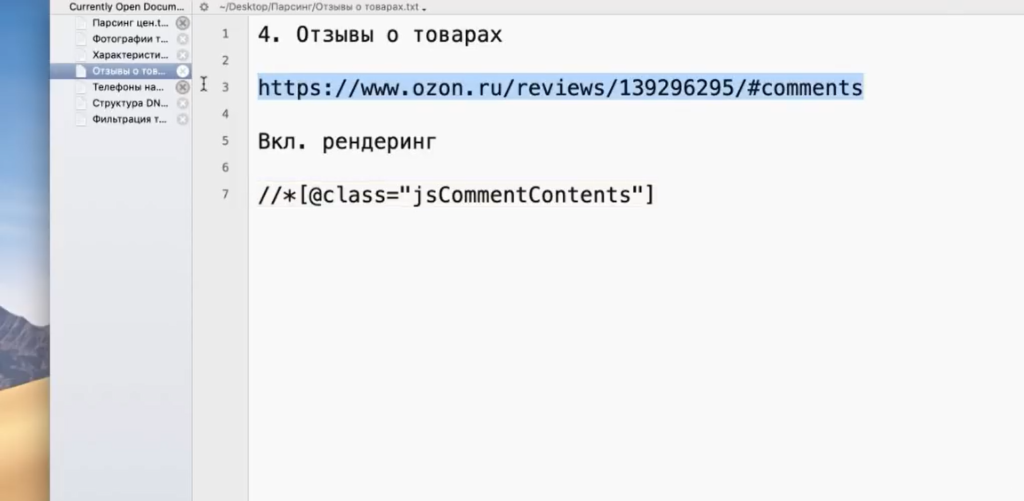
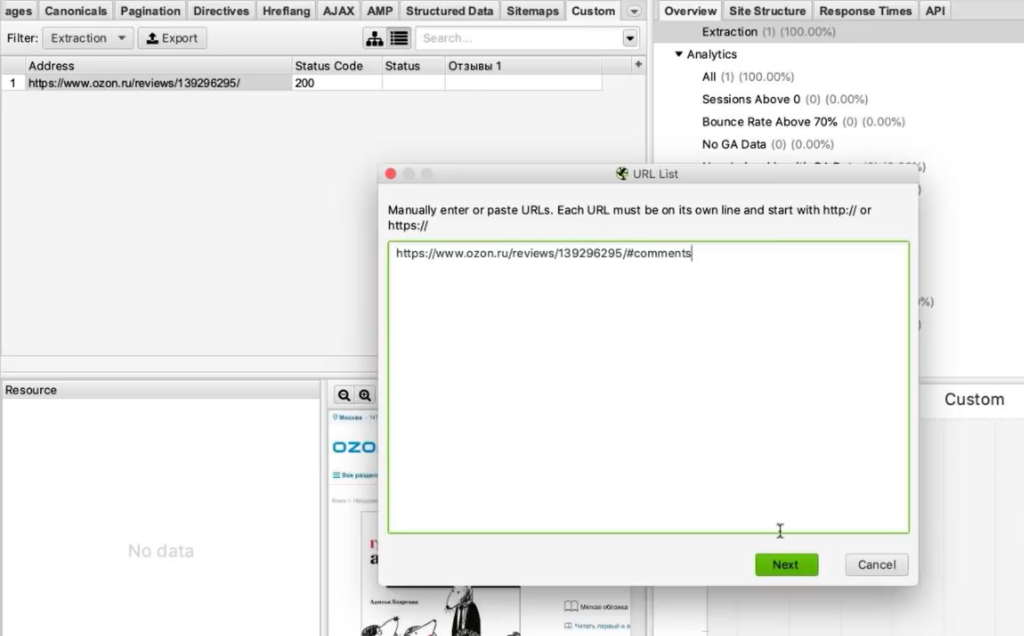
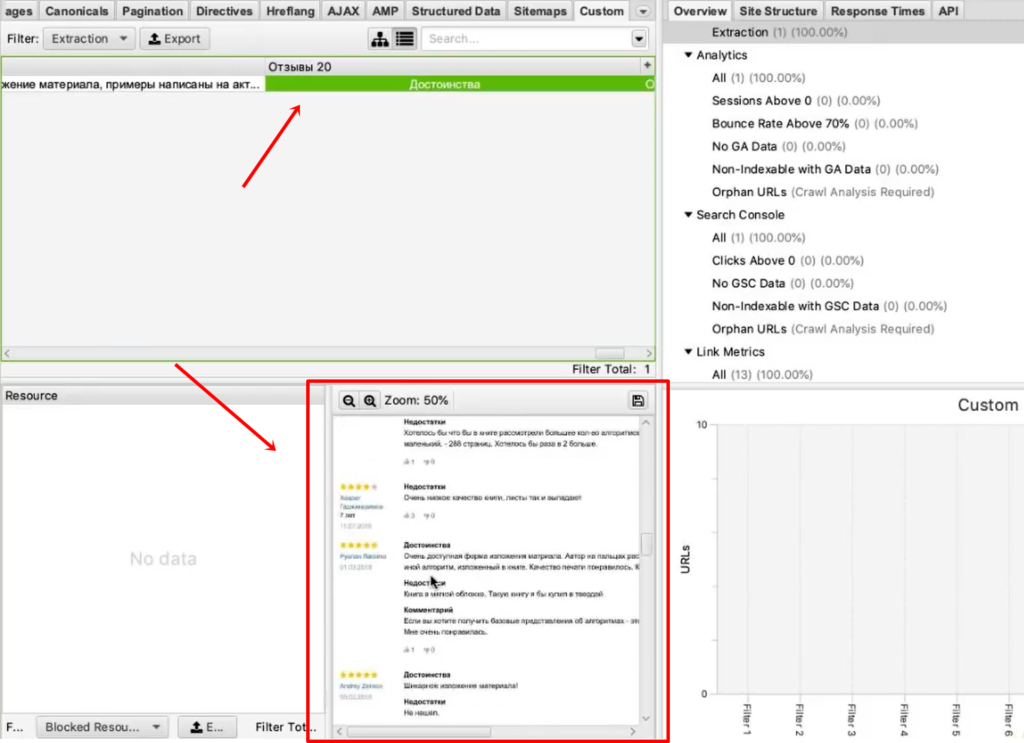
- Пример 4. Как парсить отзывы (с рендерингом)
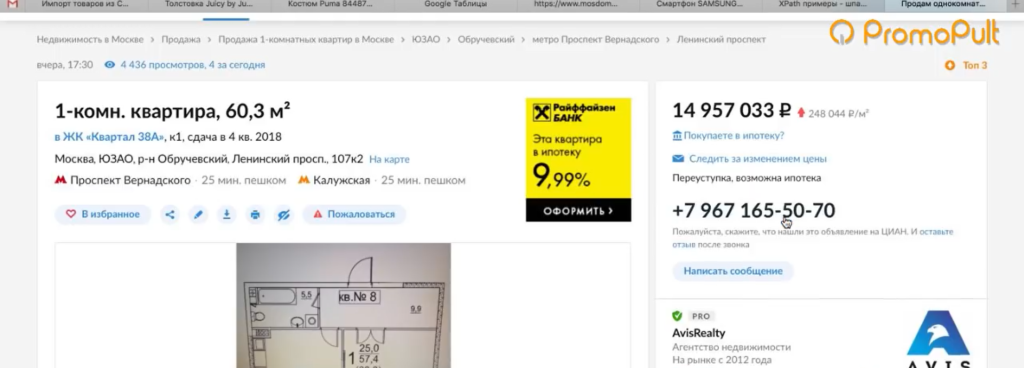
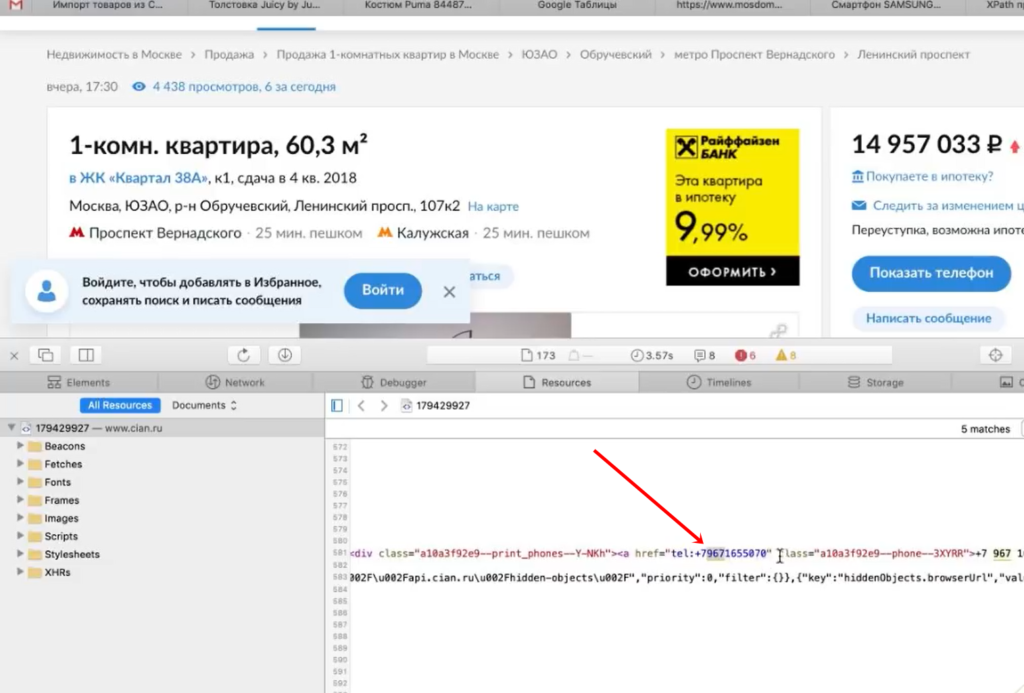
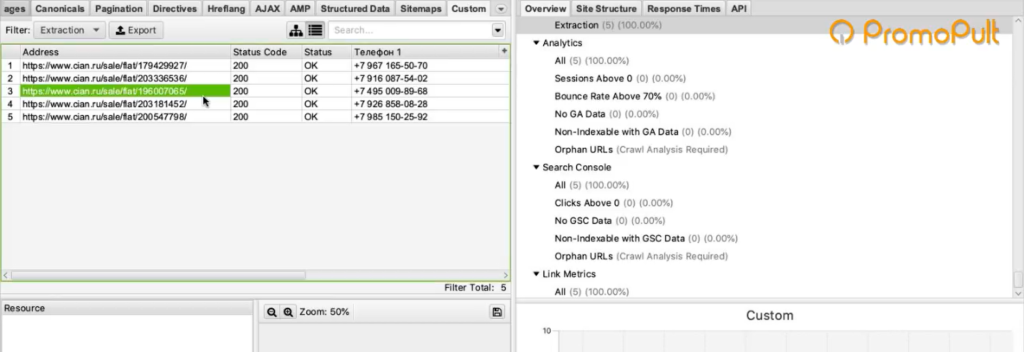
- Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
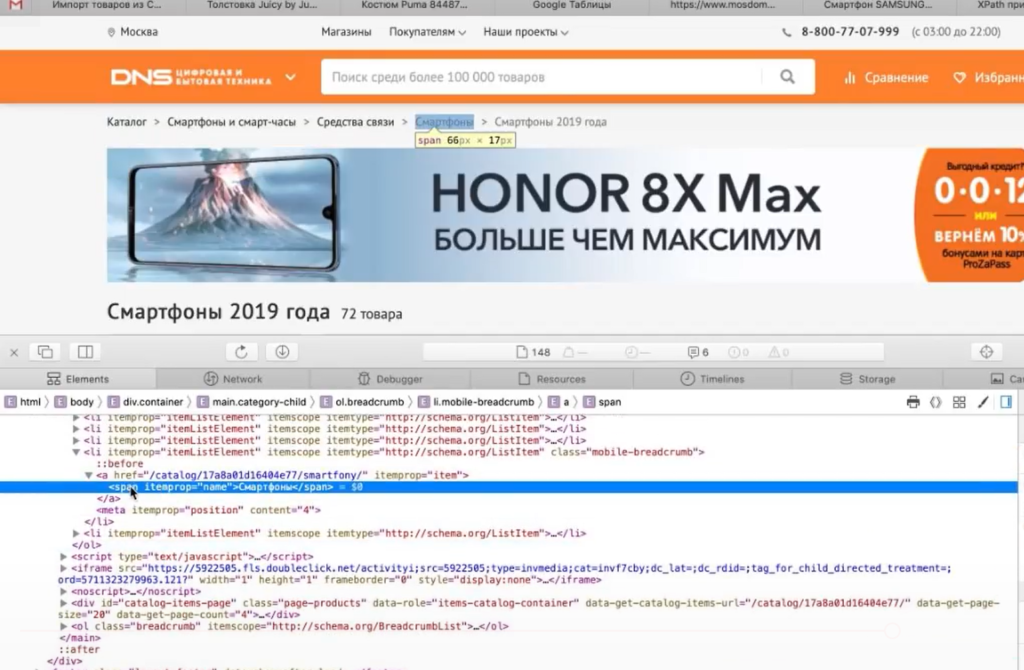
- Пример 6. Как парсить структуру сайта на примере DNS-Shop
- Возможности парсинга на основе XPath
- Ограничения при парсинге
Делаем парсеры контента своими руками
Опции темы



всевозможные доски объявлений, со спаршеным контентом живут в индексе яндекса превосходно. Несмотря на то, что инфа на многих досках дублируется, яндекс не выкидывает их из индекса, до тех пор пока вебмастер в силу природной жадности не начинает размещать всякие попандеры и прочую хрень.
Итак сейчас я покажу вам на примере, как можно быстро без особых усили и не имея навыков программирования создать такую вот досочку, скажем на 500 страниц.
Для того, что бы исключить непонятки — поясню, что под парсером я имею в виду некую прогу которая тырит контент и делает его удобоимпортируемым в наш дизайн.
Итак начнём. Для начала давайте выберем «жертву», пусть это будет какая ни будь отдельная рубрика Яндекс.каталога (о том, как разделять спаршенный контент, расскажу в слудующей статье, пока у нас будет одна категория).
Скачиваем рубрику «как есть» прогой Teleport Pro (бесплатная, делает дубликаты сайтов). качаем только контент без сохранения структуры и картинок. Это просто.
Далее выбираем движок. Предлагаю использовать DLE, устанавливаем его на денвер или на хостинг. Заходим в используемую базу, откываем таблицу где храняться все записи (в DLE это таблица dle_post в других движках другие)
В DLE нужно заполнить как минимум четыре поля:
Заголовок:title
Автор:autor
Короткий текст:short_story
Полный текст:full_story
Составляем заготовку slq запроса (для тех, кто не вкурсе — это написанная на языке sql инструкция, которую можно скопировать во вкладку slq в phpmyadmin и она что то там сделает с базой. При помощи sql запросов можно работать с базой напрямую, без всяких навороченых админок с визуальными редакторами)
она будет выглядеть так:
Где вы её найдёте, думайте сами. Но в демоверсии ограничение максимум на 100 обработанных файлов.
Открываем, сразу запускаем мастер фильтров
Выбираем самый верхний фильтр «Поиск и замена по схеме».
теперь подходим к самому основному — создание схемы по которой прога и будет выдирать нужную нам инфу. Писать мы будем на регулярных выражениях, точнее используем самую простую схему.
Открываем наш яндекс каталог в виде html и копируем кусок html кода который содержит заголовок и описание (собсно то. что нам и нужно)
Теперь нужную нам текстовую информацию заменяем вот таким образом
(.*?) — на языке регулярных выражений означает вытащить максимальное количество символов после того, что слева от скобки до того что справа от закрывающей скобки. Проще говоря — то что надо. Обратите внимание на слэши перед «нормальными» скобками, их нужно экранировать обязательно иначе прога решит, что это инструкции для неё.
Скидываем это всё в поле «найти схему», предварительно в выпадающем списке выбрав тип поиска — Схема perl, а внизу поставить галку «Извлечь соответсвия»
В поле замена на пишем наш sql запрос
Цифры $1 и $2 означают, что в это место будет вставляться содержимое первого «(.*?)» и второго «(.*?)» соответсвенно. Как видим полное и краткое описание у меня будет одинаковым.
у вас должно быть что то типа такого:
На вкладке «Зона учебного прогона», в левое поле копируем поностью html код страницы каталога-донора (откуда выдрали кусок с вхождением названия и описания сайта). Жмём «Тестовый прогон», если получилось что то типа этого, значит всё ок.
Возвращаемся на первую вкладку, Файл вывода ставим «выводить в один файл».
На вкладке «файлов в обработке», указываем папку куда скачали сайт через teleport pro. Запускаем!
Если всё ок, то в указанной нами файле будет сохранён дамп со всеми найденными соответствиями схеме. Теперь просто импортируем через phpmyadmin (вкладка импорт) этот файл в базу. Готово!
 Миниатюры
Миниатюры
Источник
Учимся писать парсер сайта своими руками
Сегодня я приведу вам в пример, который возможно понадобиться начинающим парсерам и возможно вы найдете в нем ценную информацию. В комментариях очень хотелось бы увидеть возможные изменения для упрощения задачи, так что всегда рад услышать ваши мнения.
Передо мной стояла задача заполнить интернет магазин товарами в количестве свыше 50 тыс наименований. Оригиналы товаров лежали на сайтах поставщиков.
Особо заморачиваться с кодом и решением я не стал, поэтому сделал все максимально просто и быстро.
Прикрепленные файлы буду выкладывать на проекте моих друзей и партнеров 2file.ru Будьте уверены что все ссылки всегда будут действующими и вы всегда сможете скачать любой файл из данной инструкции. +размер файлов не ограничен, нет времени ожидания и нет рекламмы.
Первым делом я решил скачать полностью сайт себе чтобы в дальнейшем было проще работать с ним.
Для Windows нам потребуется программа wget (КАЧАЕМ)
Распаковываем например на диск С и для удобства переименовываем в wget.
Далее нажимаем пуск-выполнить-cmd и там вводим CD C:\wget\. Далее нам нужно запустить команду wget.exe -c -p -r -l0 -np -N -k -nv АДРЕС САЙТА 2>wget.log. Описание команд -c -p -r -l0 -np -N -k -nv можно подробно почитать ТУТ. Нажимаем enter и начинается скачивание. В папке wget появляется папка с названием сайта, куда сливается сайт. ВНИМАНИЕ, при больших объемах, сайт может скачиваться даже несколько дней.
. Прошло несколько дней…
Вот мы и дождались загрузки сайта на наш компьютер. В моем случаи в корне находились страницы с подробным описанием товаров, так что буду следовать отсюда.
Нам понадобится установленный на компьютере сервер apache+php. Для удобства и быстроты настройки можно использовать например xampp, который можно взять бесплатно на ЭТОМ сайте, где так-же приведен процесс инсталяции.
Ок, теперь у нас стоит апач, есть скачанный сайт. Далее для удобства я перенес все скачанные странички в папку xampp для дальнейшей работы с ними. Чтобы не усложнять код, я переименовал все страницы в порядковые номера чтобы получилось 1.html, 2.html… и так далее. Сделать это очень просто. Например через total commender в меню файлы-групповое переименование. Далее в папке с переименованными страницами я создал index.php файл. Теперь начнем разбираться в коде:
(.+?.) #is’, $html, $matches );
foreach ( $matches[1] as $value ) echo $value.’<br>’;
?>
Первой строчкой я указываю на открытие 132.html, в котором будет осуществляться выборка данных.
Открыв любую скачанную страницу, мы видим что интересующая нас информация находится между тегами.
Один из моих примеров это
preg_match_all( ‘#(.+?.)#is’, $html, $matches );
Далее осуществляется вывод полученных данных на экран и спуск на строчку вниз br.
Для выдирания нескольких результатов из одной страницы, можно использовать код на подобии:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
?>
Должно получится что-то вроде (значение1, значение2, значение3 <br>)
Теперь немного дополним наш код чтобы прогнать все наши скачанные страницы. Решил сделать с помощью цикла и получилось что-то вроде этого:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
Отлично, теперь мы видим что-то вроде этого:
значение#значение#значение
значение#значение#значение
Для удобства дальнейшей работы я использовал #. Теперь копируем все что получилось, загоняем в excel, нажимаем данные-текст по столбцам и ставим # в качестве разделителя столбцов. Отлично, мы получили таблицу с результатами нашего парсинга. УРА
Дальнейшая работа зависит от вашей фантазии и цели. Спасибо за внимания, надеюсь на инвайт.
Источник
Парсинг любого сайта «для чайников»: ни строчки программного кода
Разбираем тонкости парсинга данных в Screaming Frog Seo Spider
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.

ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
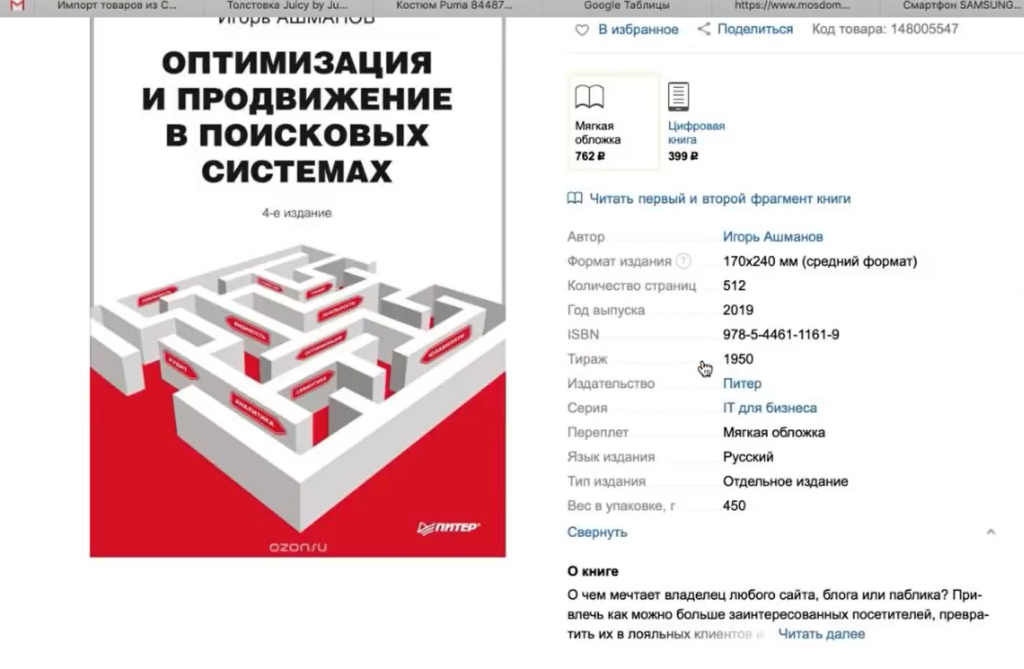
Возьмем для примера сайт mosdommebel.ru.
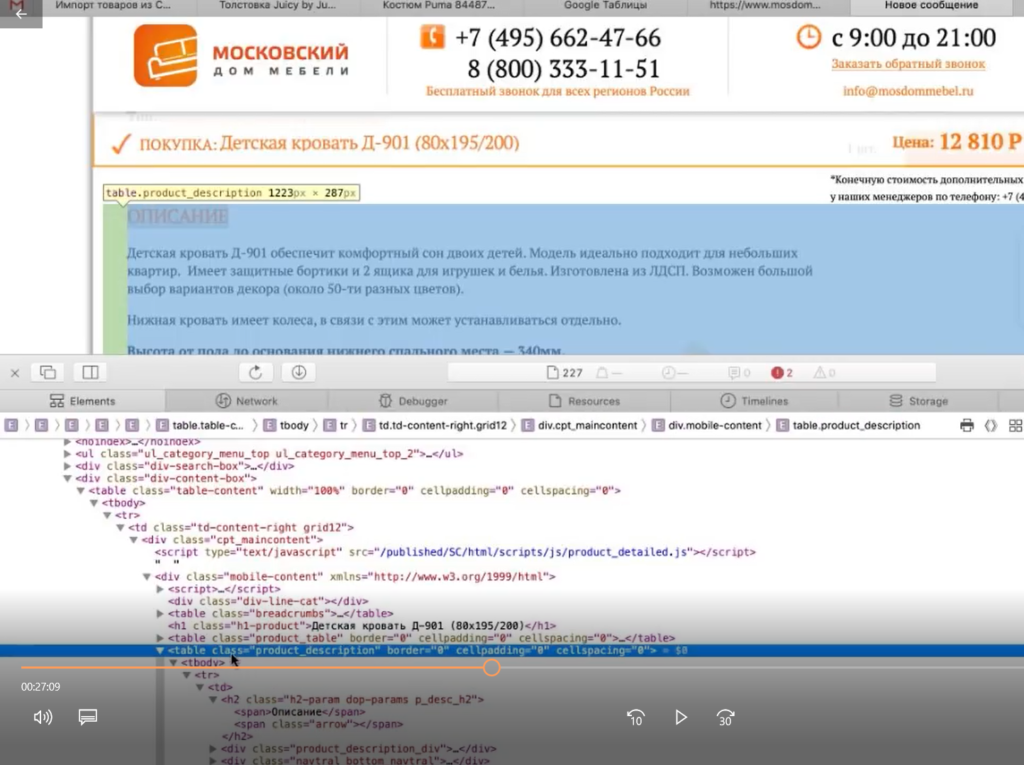
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
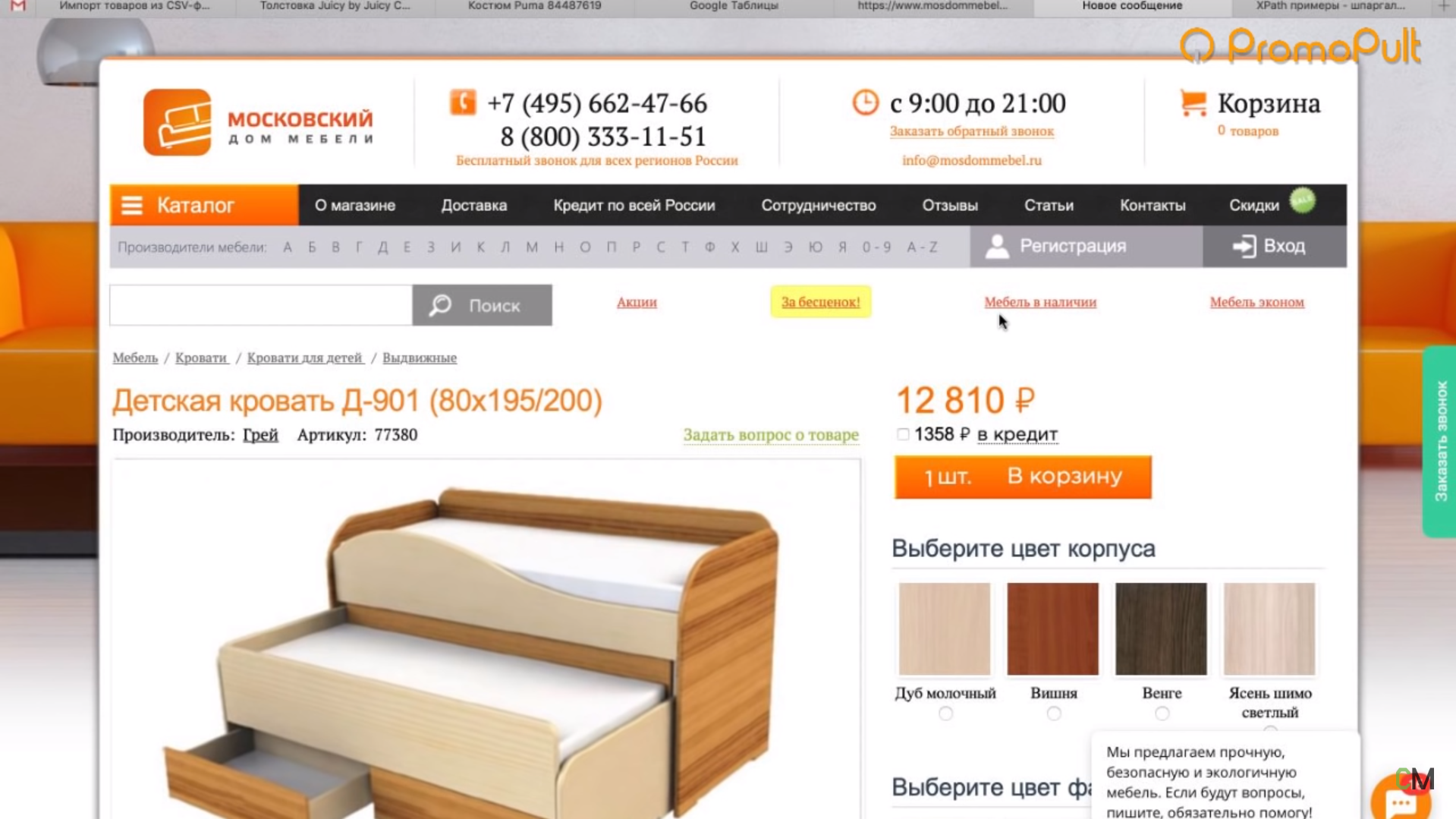
Мы видим, что цена отображается вверху справа, напротив заголовка h1. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
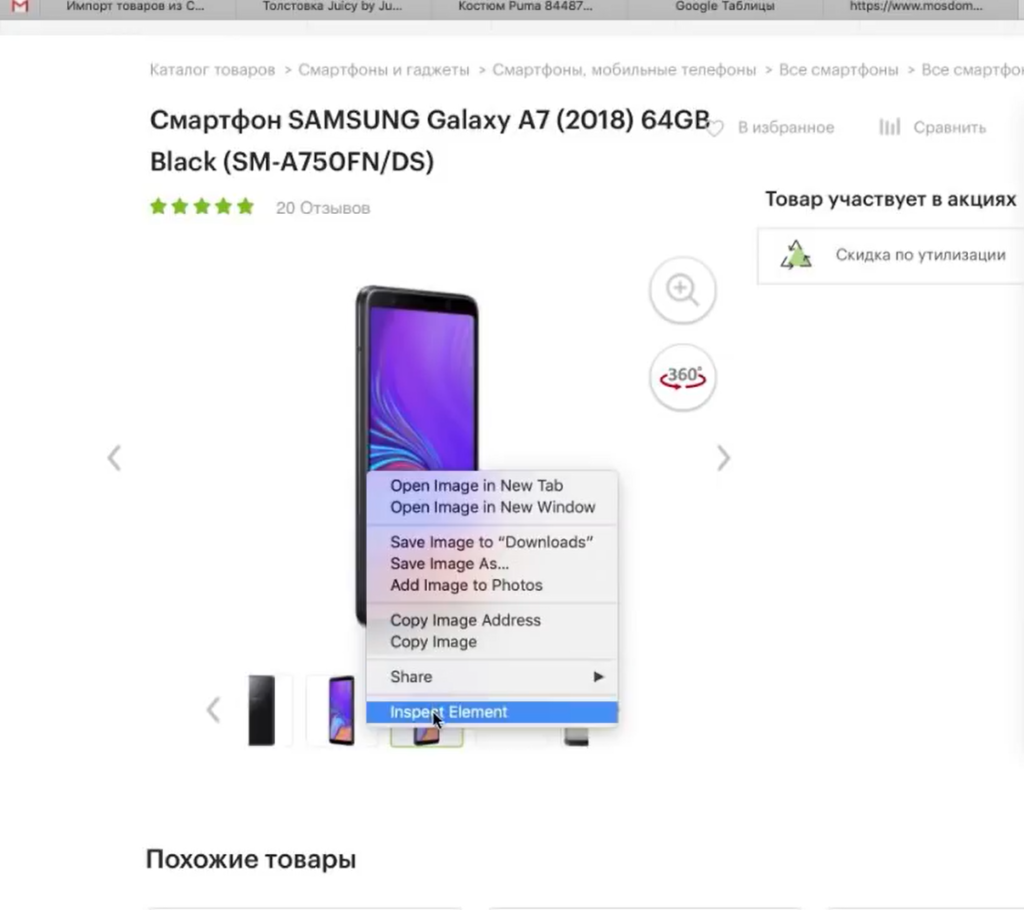
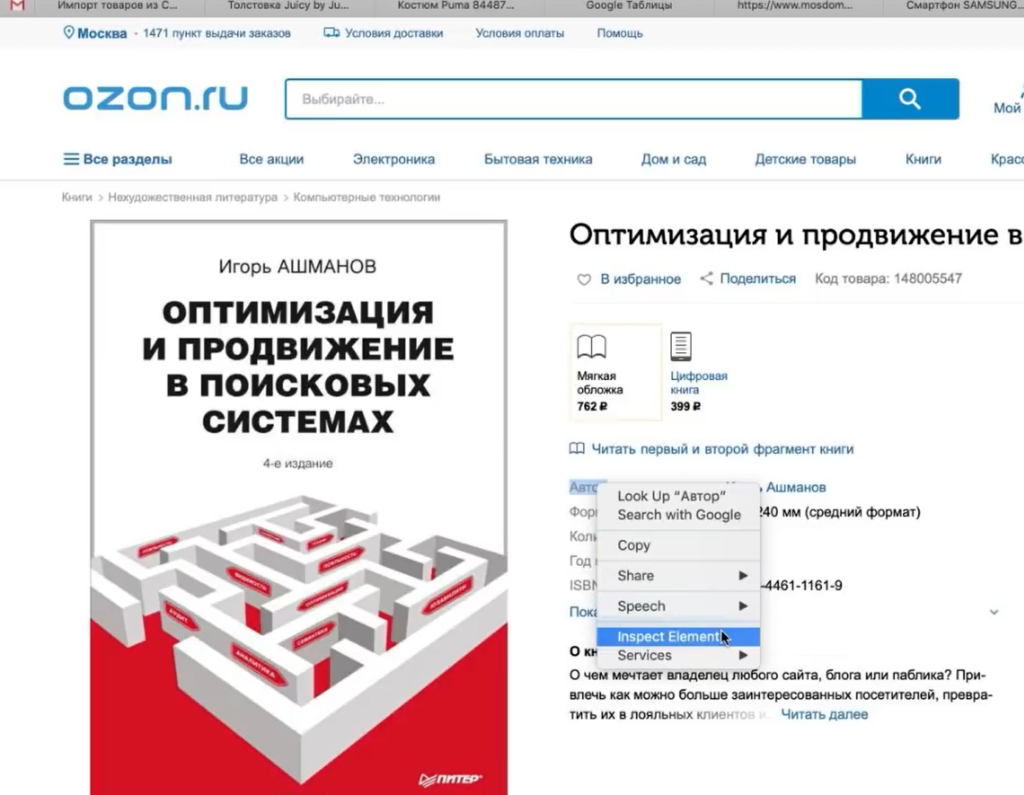
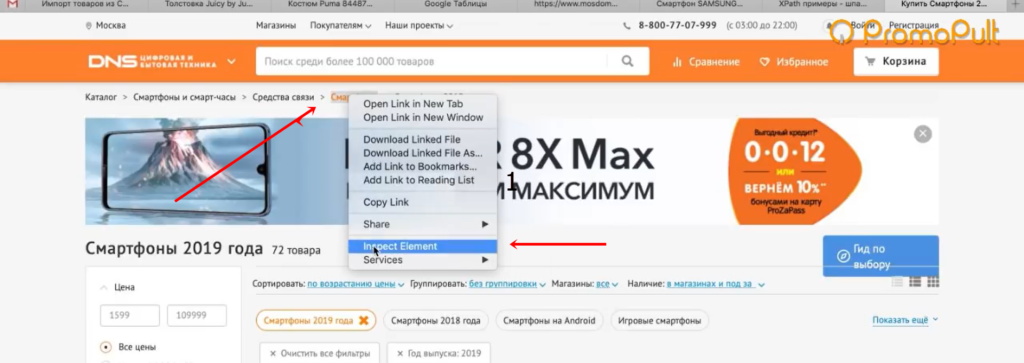
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
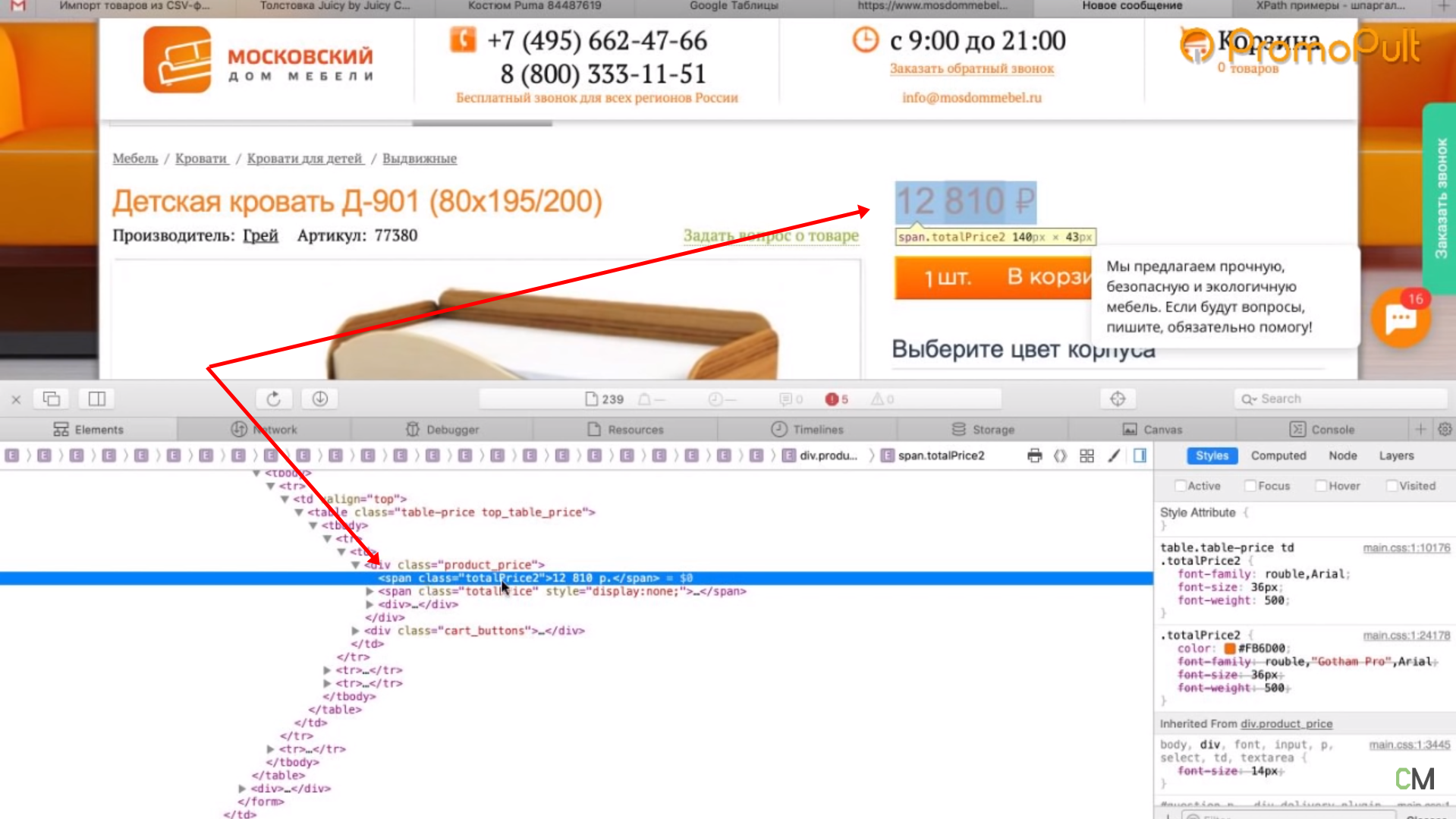
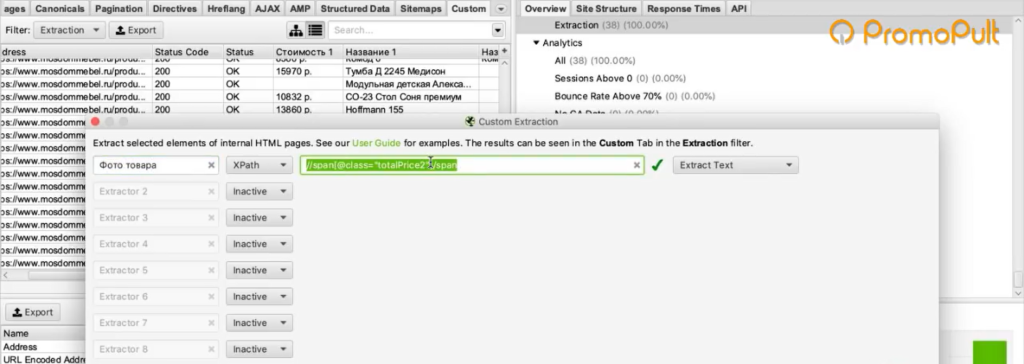
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
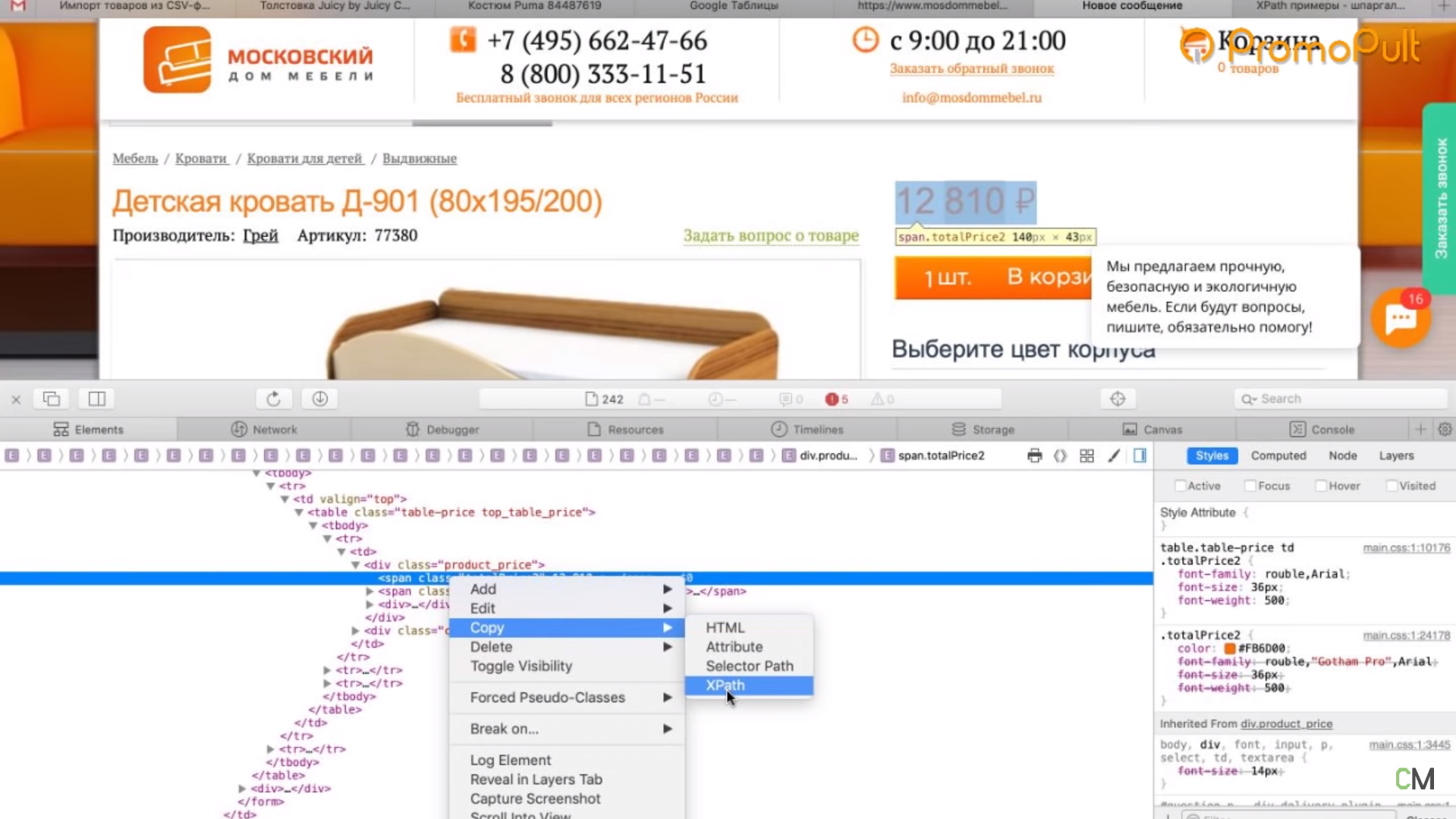
Выглядит она так:
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
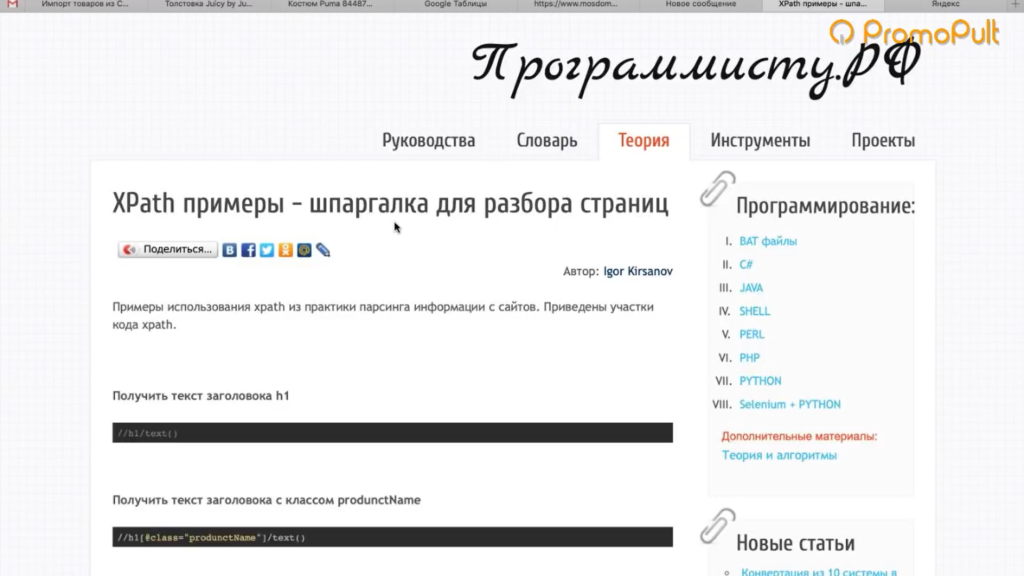
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h1, нам нужно написать вот так:
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
То есть поставить «//» как обращение к некому элементу на странице, написать тег h1 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
 Интерфейс Screaming Frog Seo Spider
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h1, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
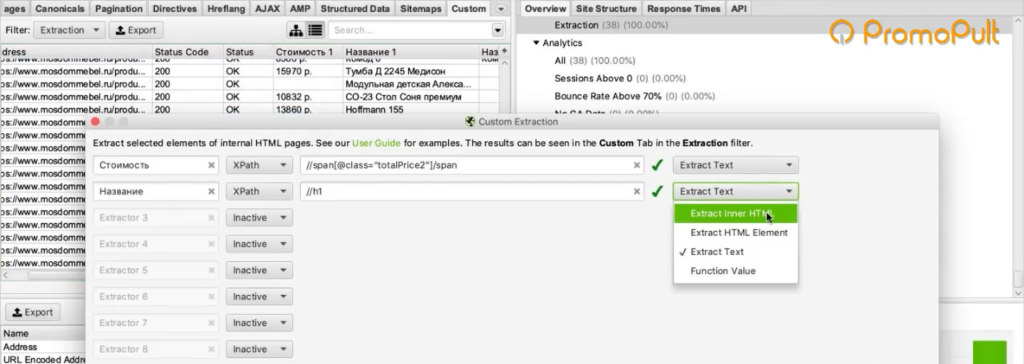
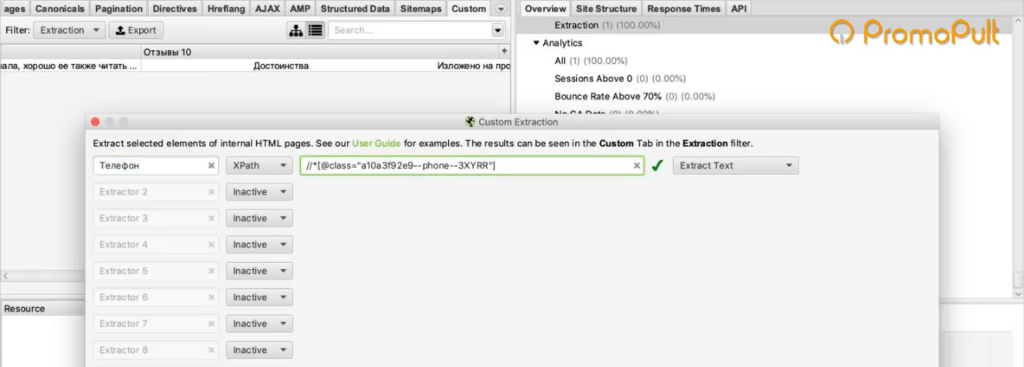
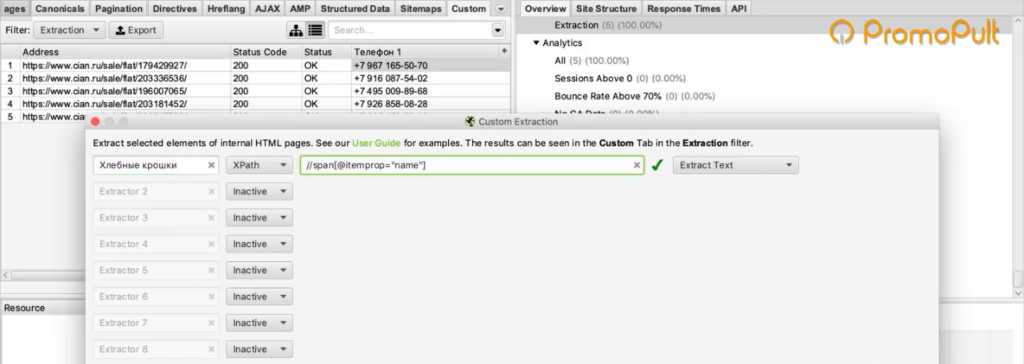
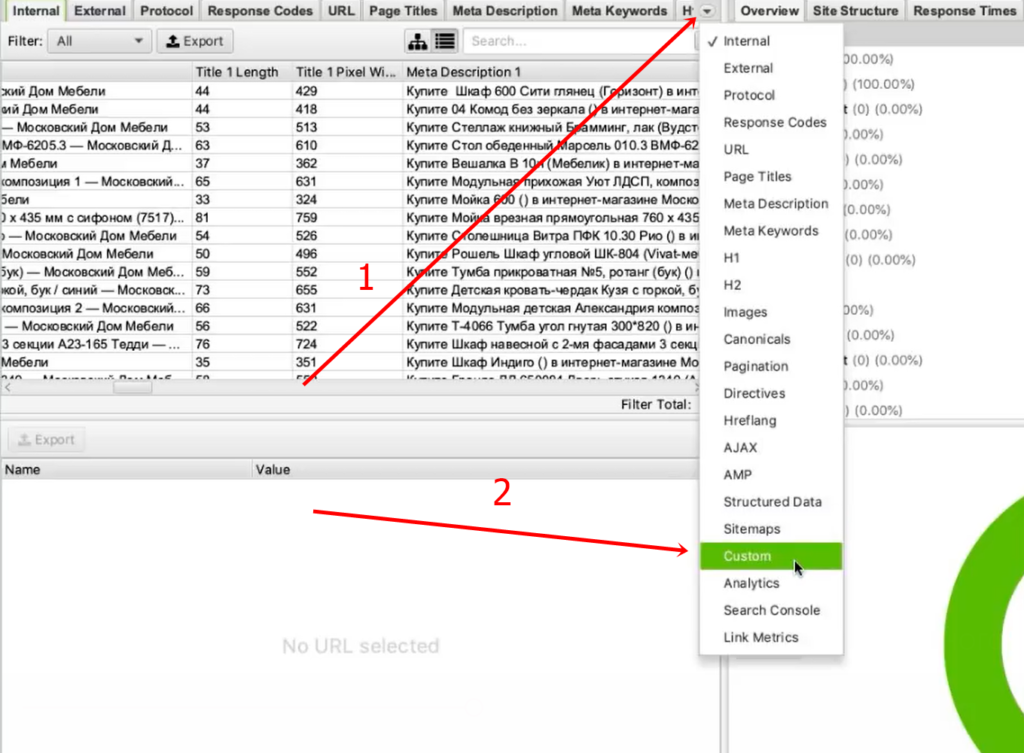
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
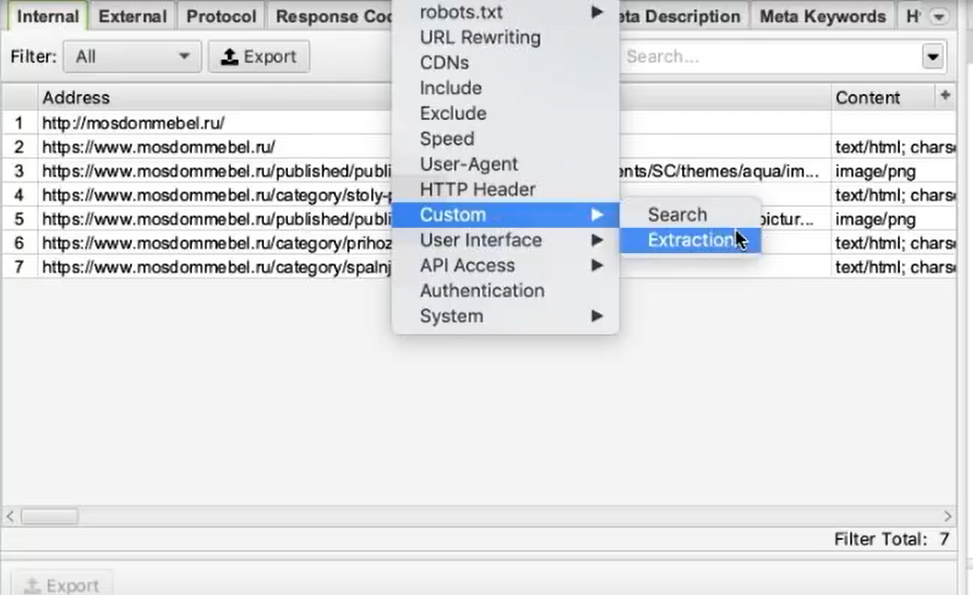
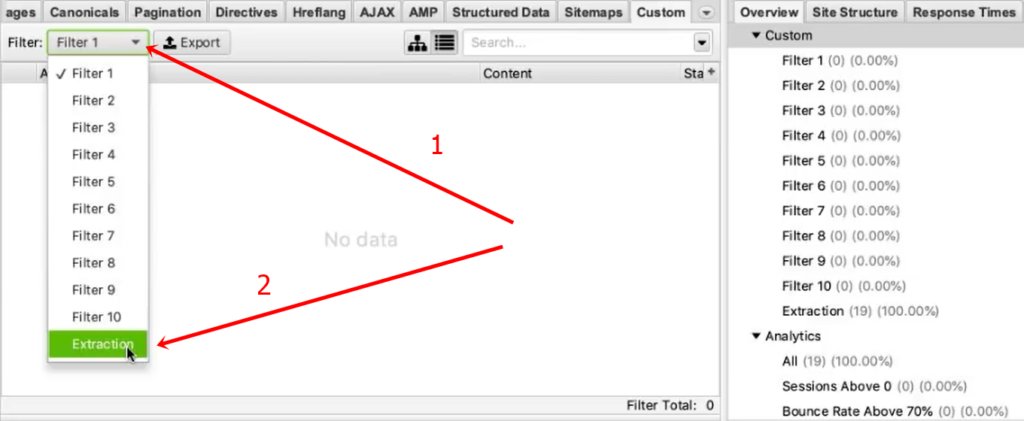
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
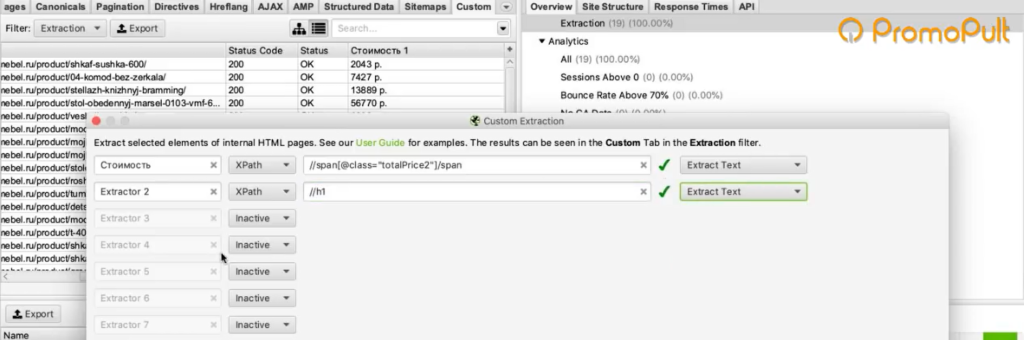
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом с классом totalPrice2. Формируем вот такой XPath запрос:
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
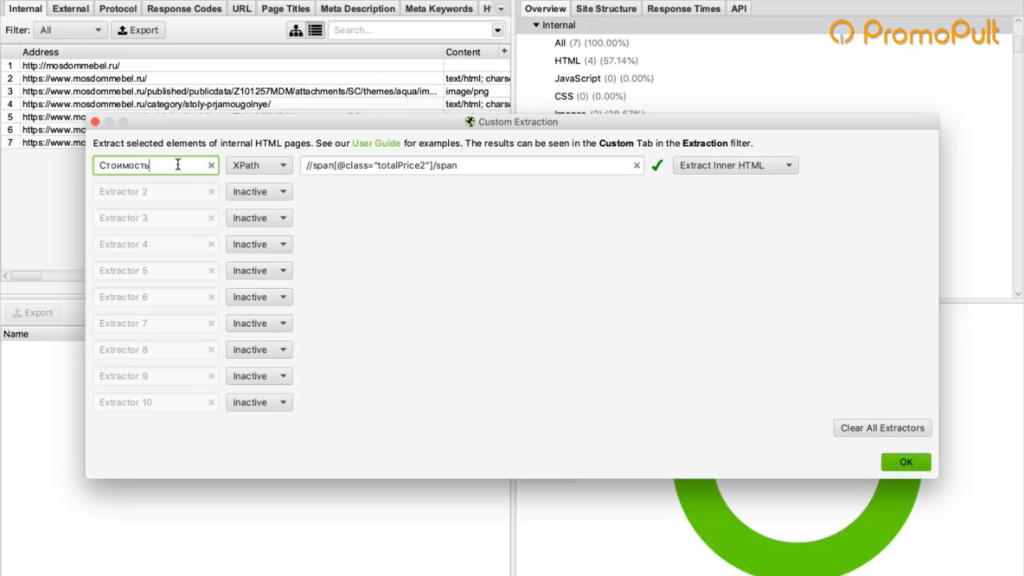
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
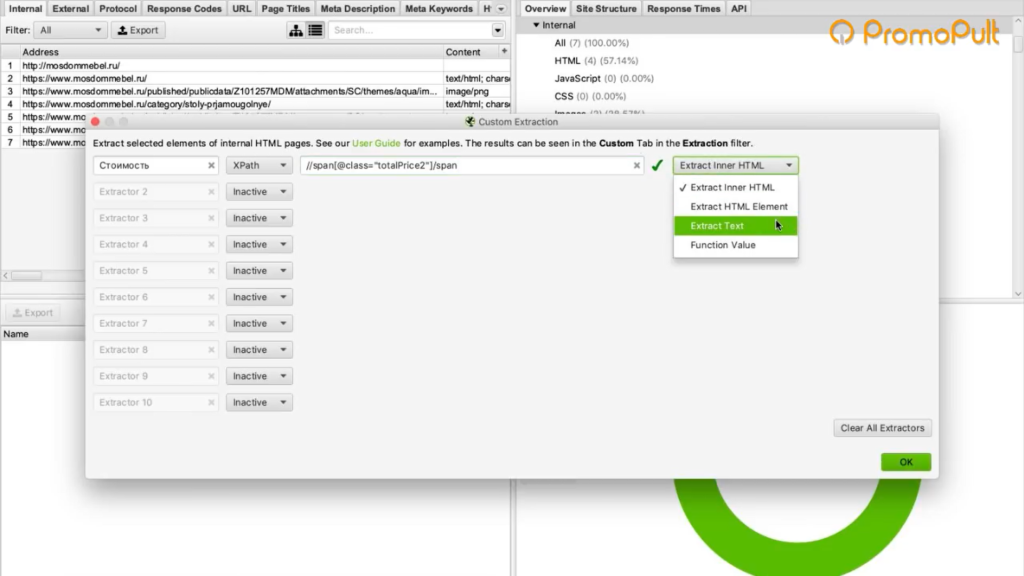
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
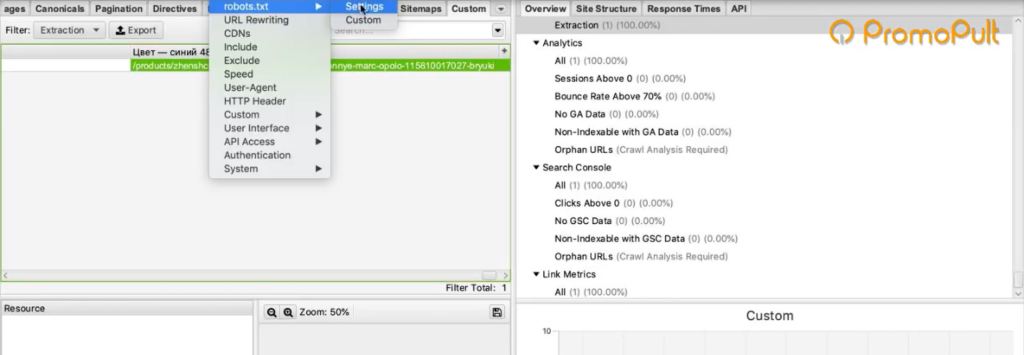
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
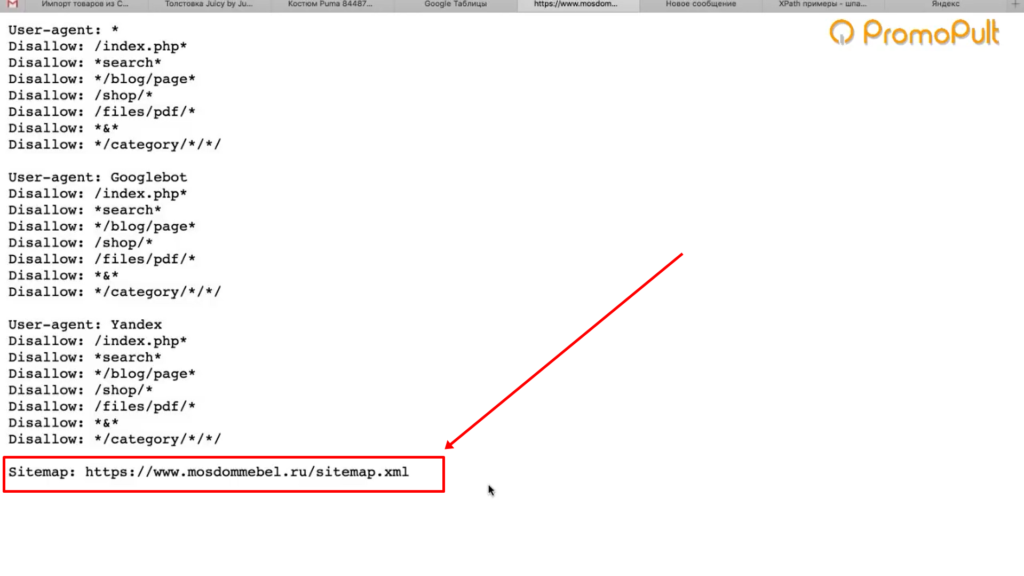 Ссылка на карту сайта в файле robots.txt
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
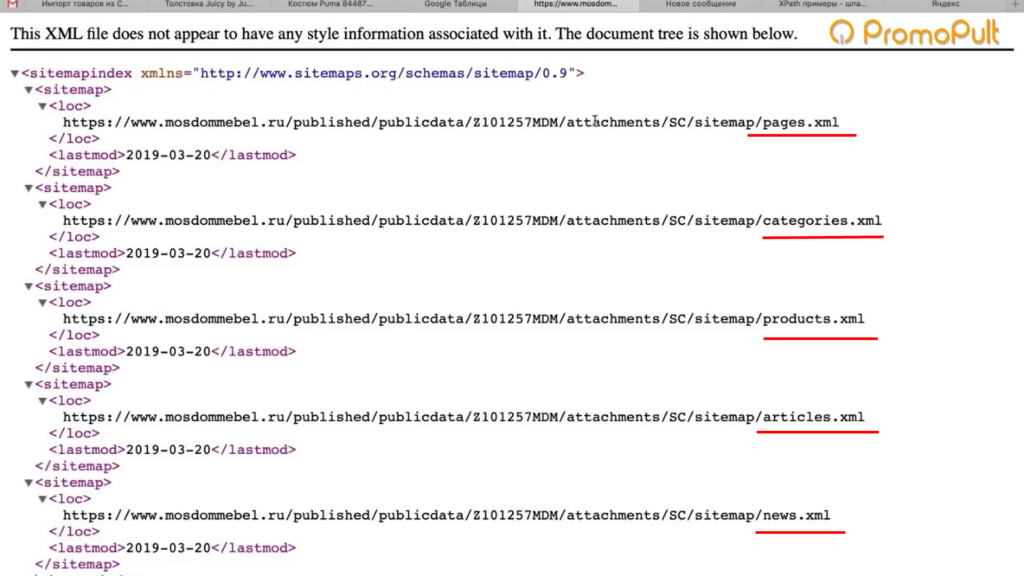 Ссылки на отдельные sitemap-файлы под все типы страниц
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
 Ссылка на sitemap-файл для карточек товара
Ссылка на sitemap-файл для карточек товара
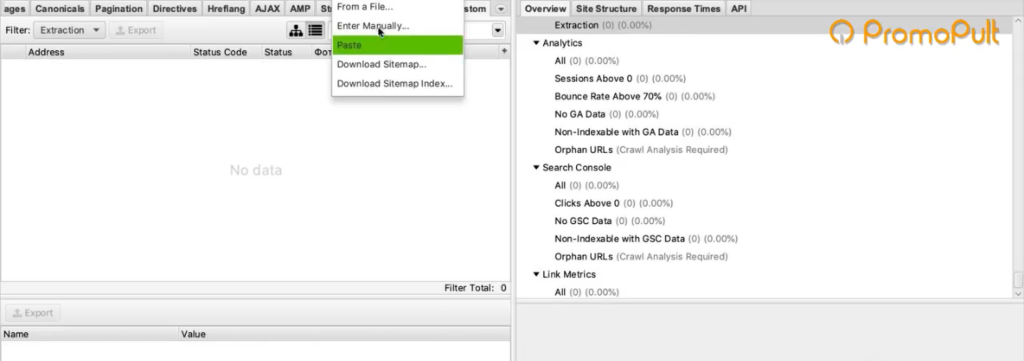
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
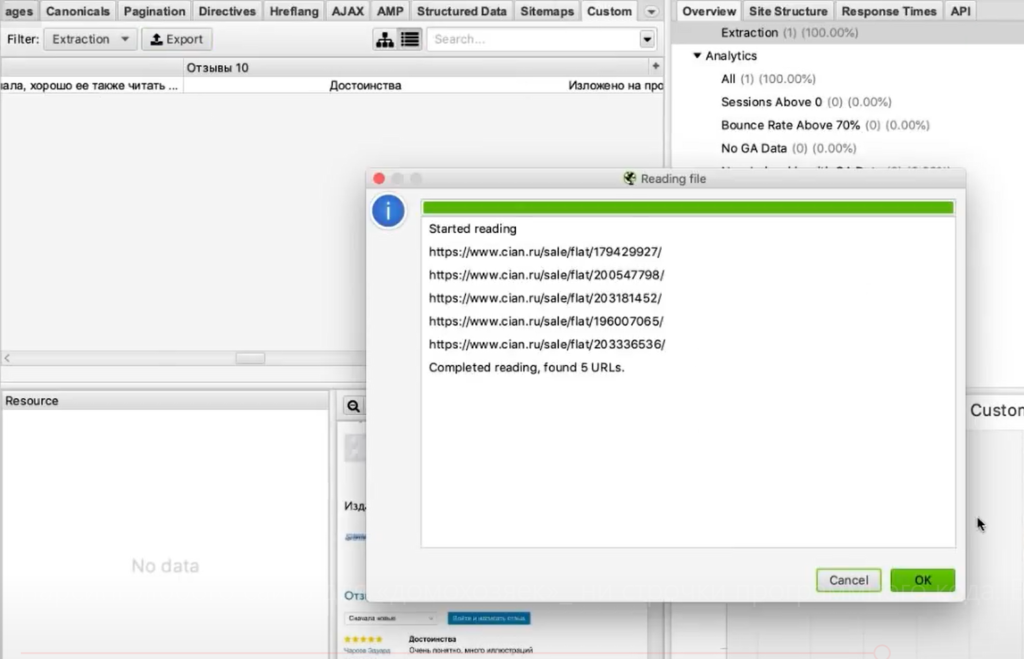
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.

Жмем кнопку Upload и кликаем по Download Sitemap.

Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
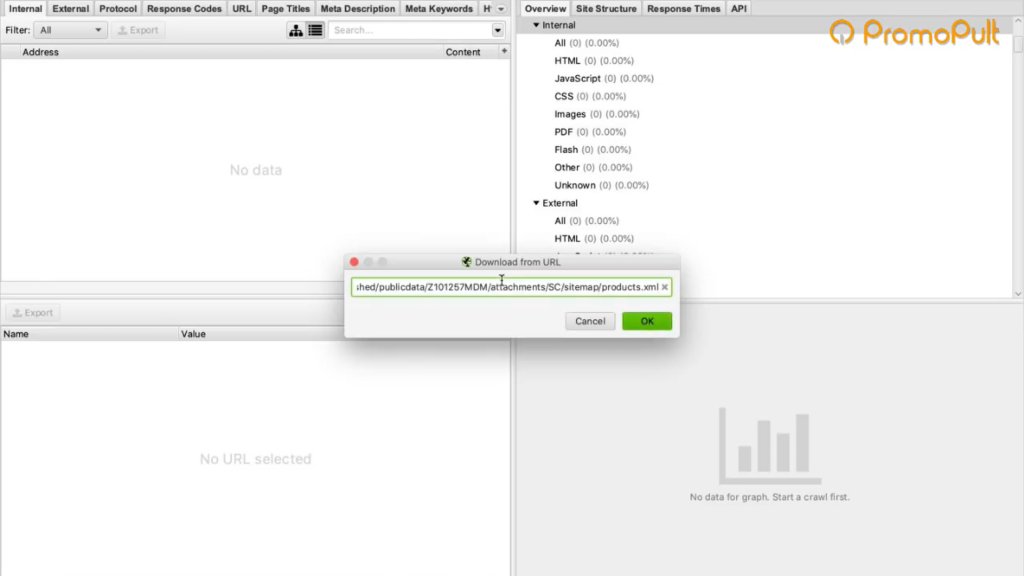
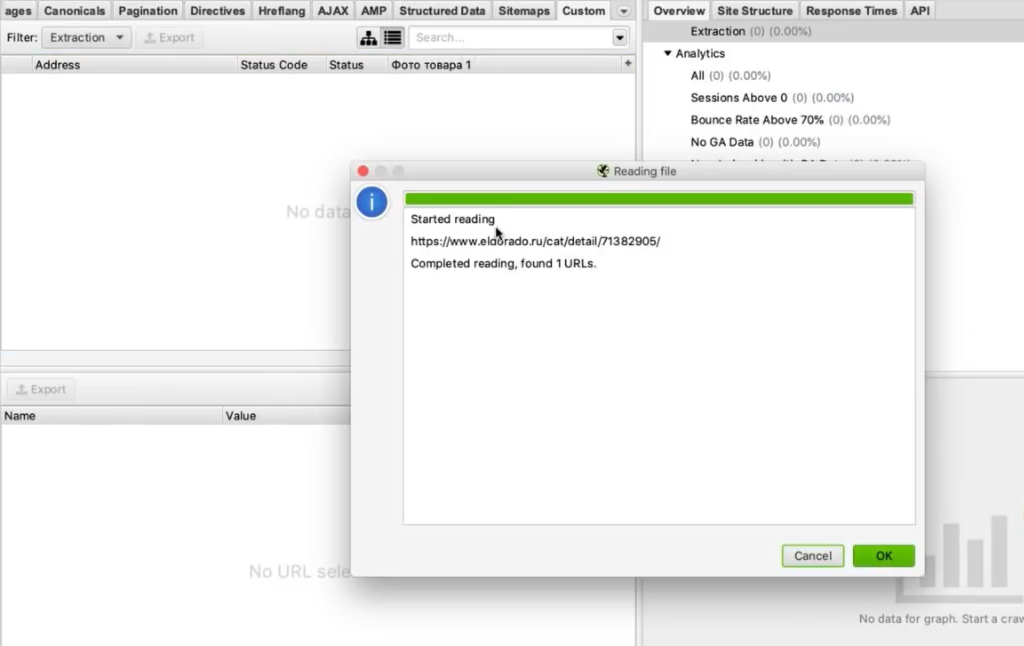
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
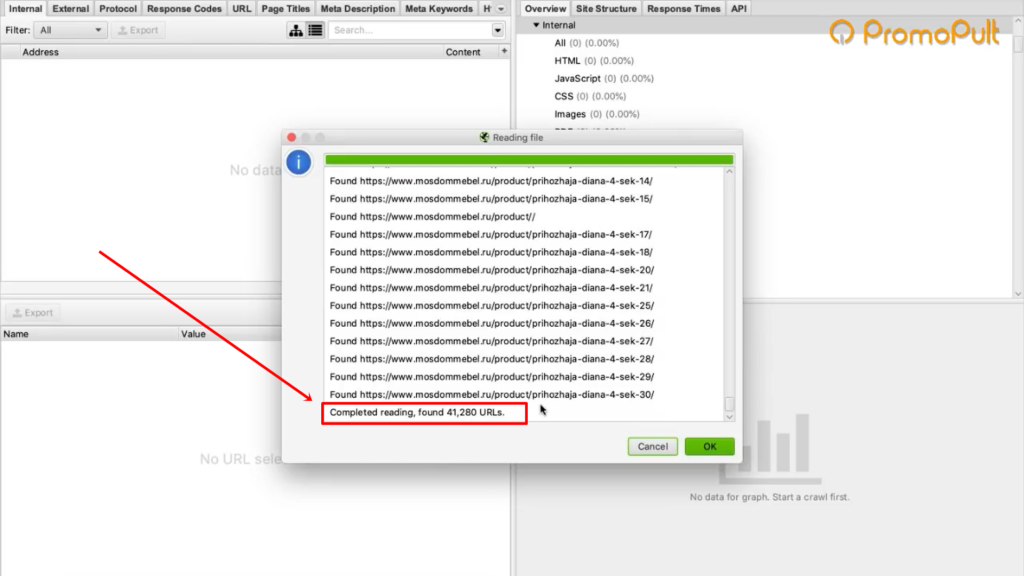
Нажимаем ОК, и у нас начинается парсинг сайта.
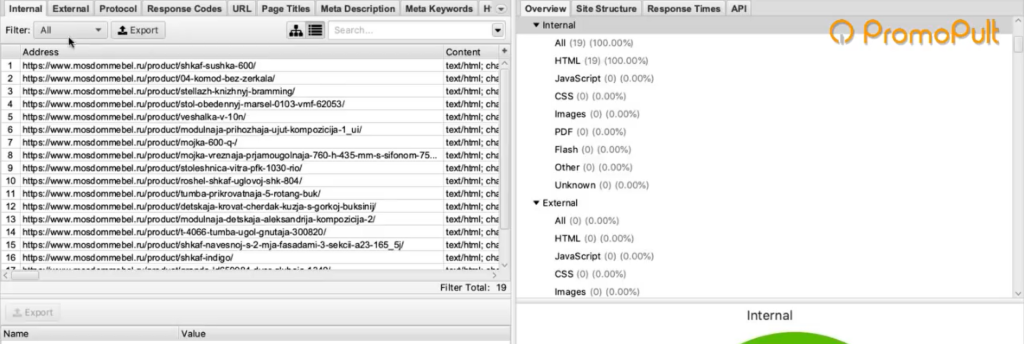
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
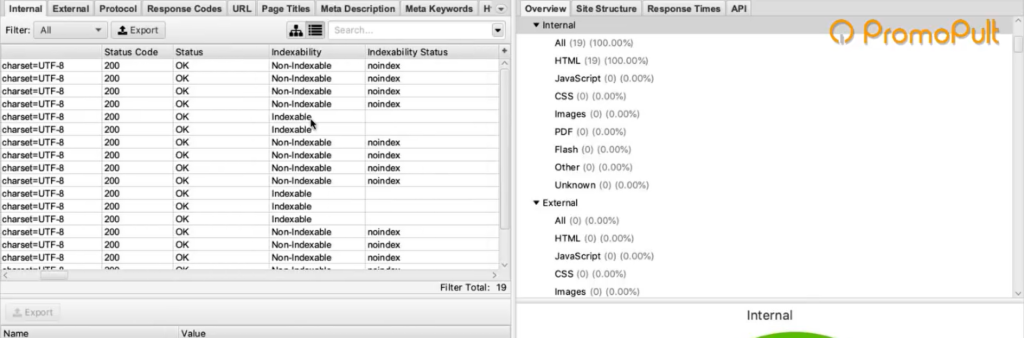
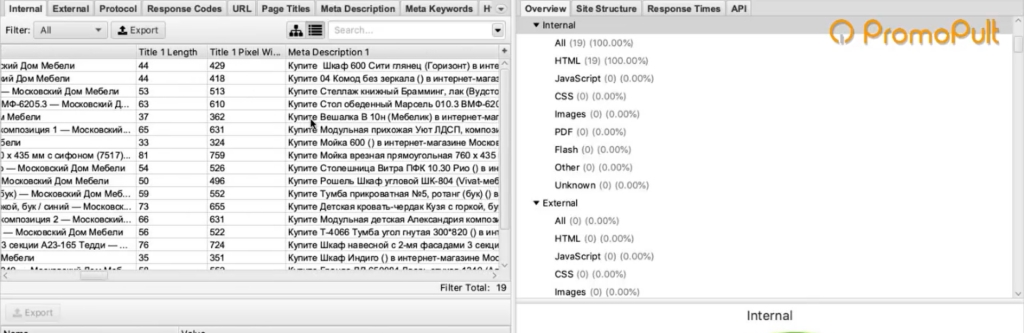
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
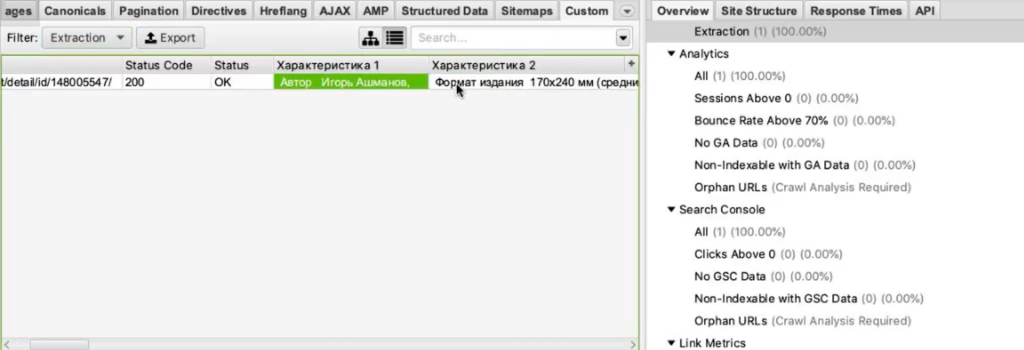
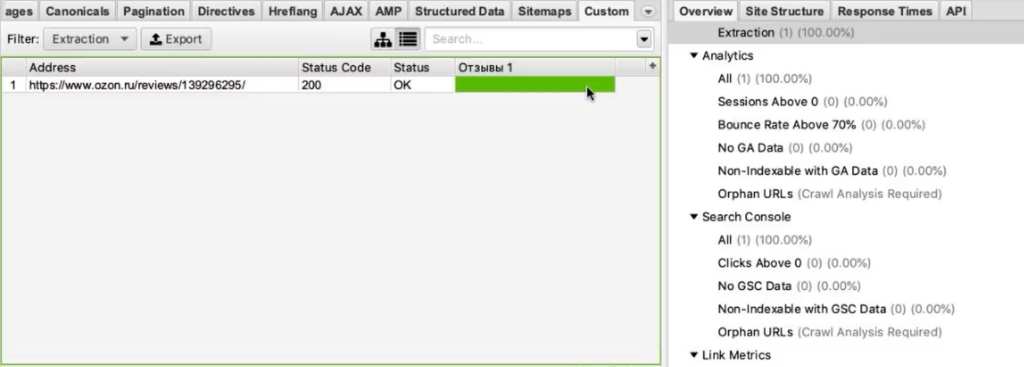
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
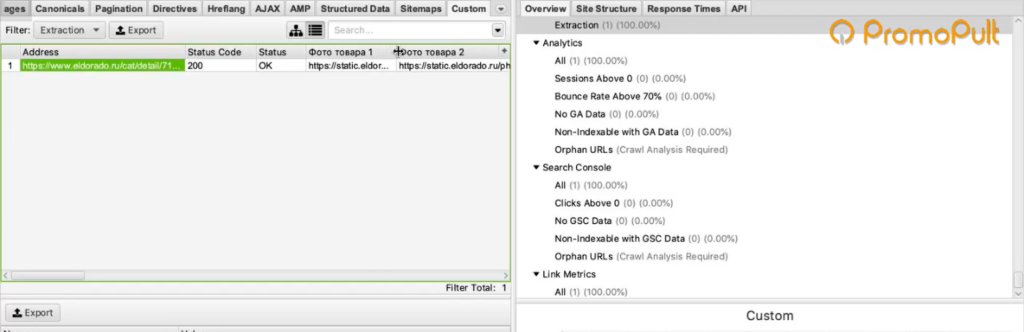
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
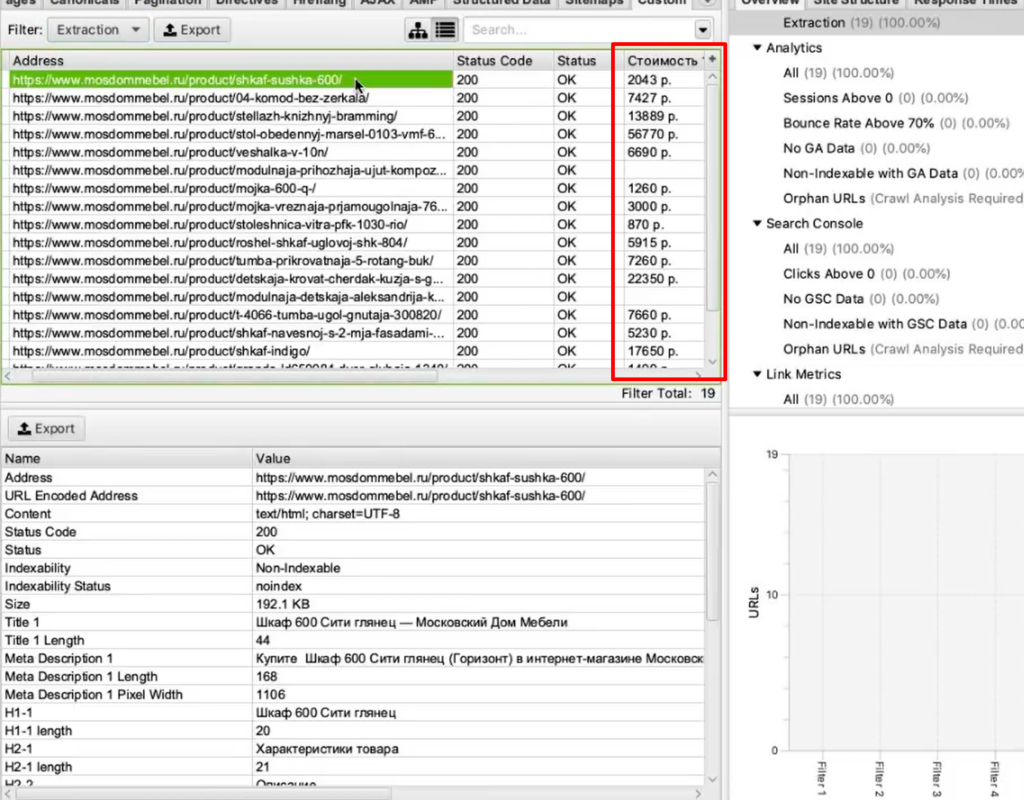
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
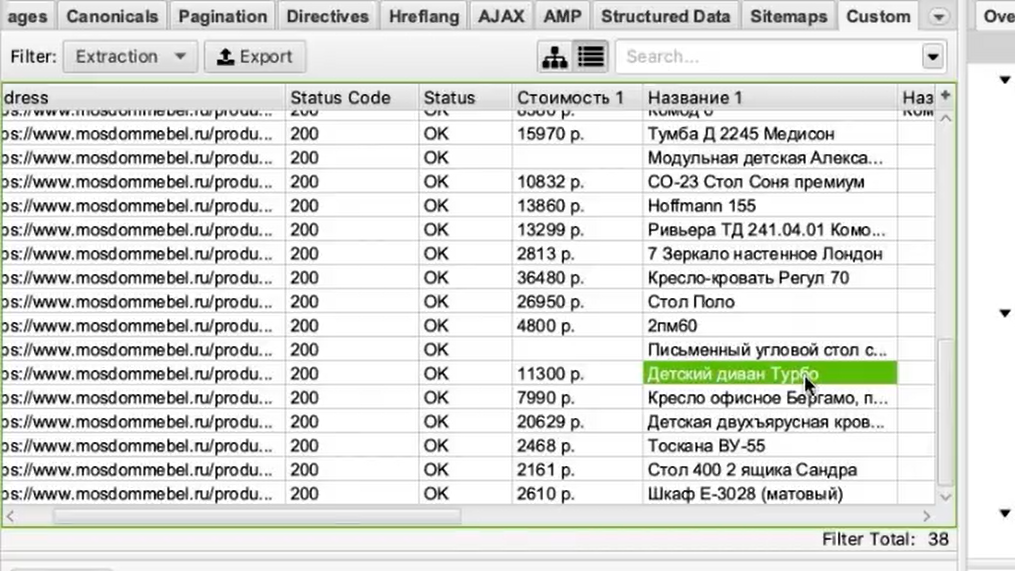
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
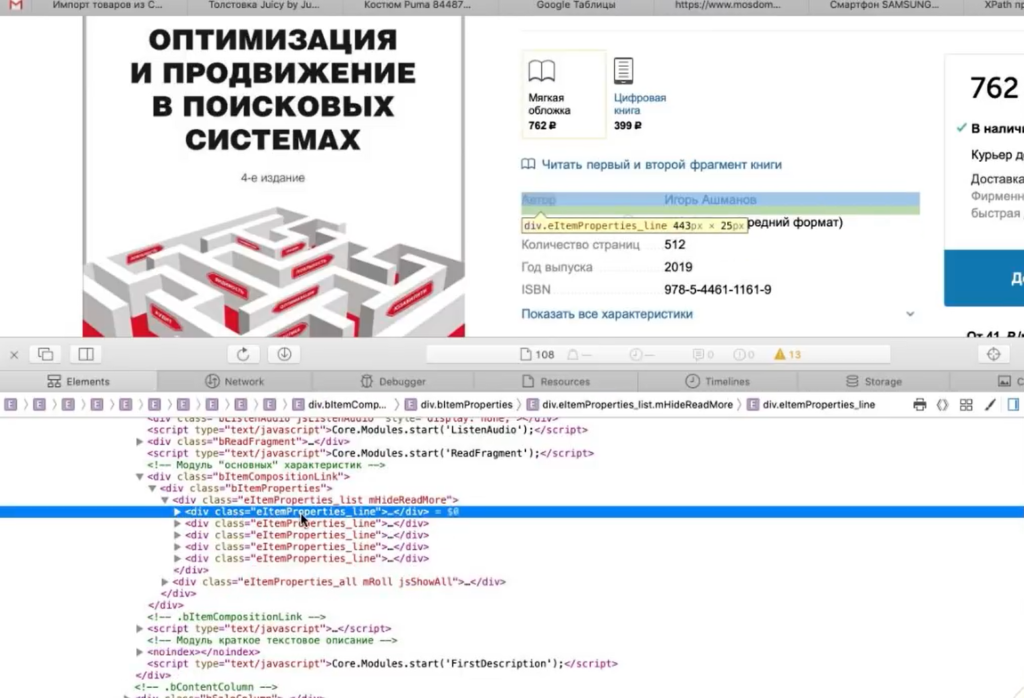
Важный момент: h1 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
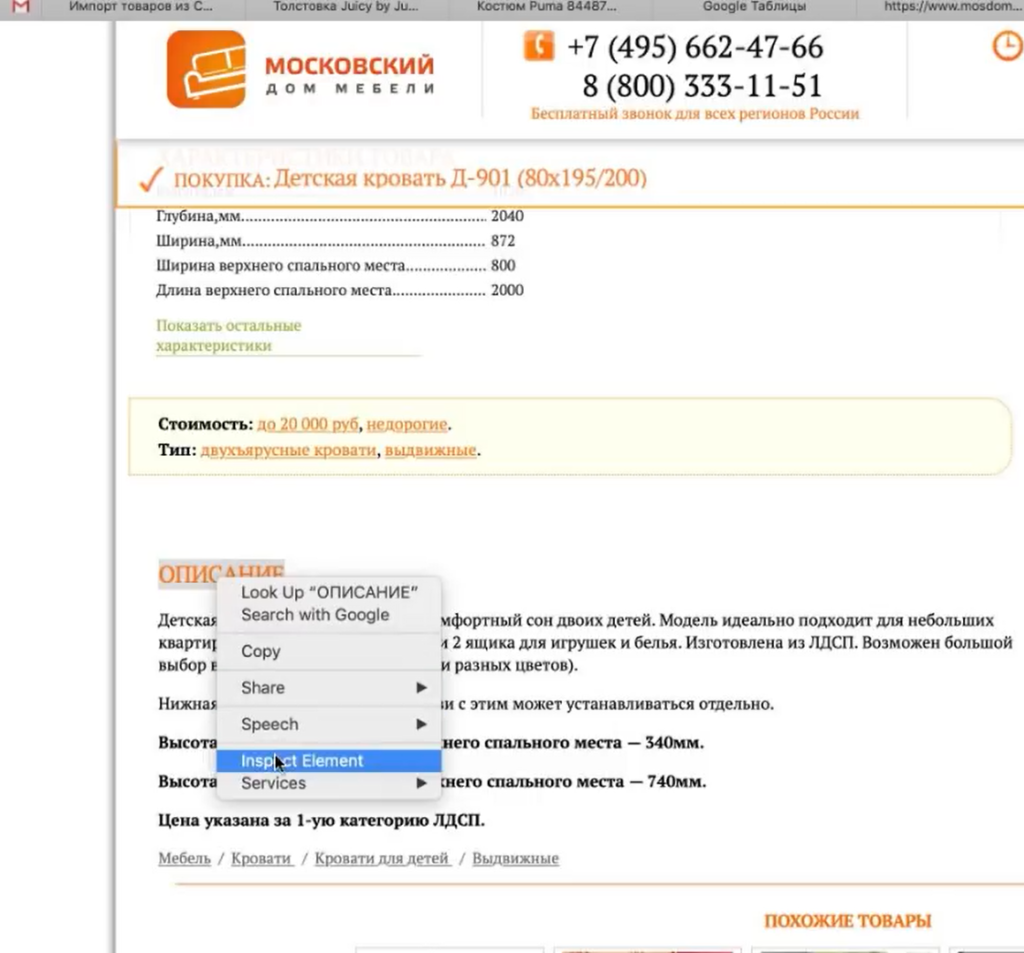
Оказывается, все описание товара лежит в теге