- НЕЙРОСЕТЬ: просто о сложном! Создание нейронной сети на Python
- Искусственный интеллект
- Машинное обучение и глубокое обучение
- Задача классификации
- Почем Python?
- Разработка нейронной сети
- Изучение программирования
- Нейронные сети на Python: как написать и обучить
- Как написать свой нейрон
- Как собрать нейросеть из нейронов
- Код нейросети
- Обучение нейронной сети
- Прямое распространение
- Обратное распространение
- Создание простой нейронной сети на Python
- Шаг 1: импорт NumPy, Scikit-learn и Matplotlib
- Шаг 2: создание обучающей и контрольной выборок
- Шаг 3: масштабирование данных
- Шаг 4: Создание класса нейронной сети
- Шаг 4.1: создание функции инициализации
НЕЙРОСЕТЬ: просто о сложном! Создание нейронной сети на Python
Нейронные сети, машинное обучение, искусственный интеллект – все эти понятия крепко вошли в нашу жизнь. В статье мы изучим работу с нейросетями, а также создадим свою на Python.
Какие невероятные возможности открываются перед человеком при правильном и разумном применении машинного обучения, нейронных сетей и искусственного интеллекта в целом.
Обычный человек даже не замечает как часто и много он сталкивается с различного рода искусственным интеллектом в повседневной жизни. На самом деле, машинное обучение повсюду: в голосовых помощниках (Siri, Алекса, Кортана), на сайтах, в соц сетях, машинах и даже в том же Google переводчике. Там он используется, чтобы в случае непонимания слова перевести его на любой доступный язык, а далее с того языка переводить на искомый вариант. Это дает им возможность создать переводчик практически для всех языков мира.
При этом всем, до сих пор может показаться, что нейронные сети и машинное обучение где-то далеко, где-то в Калифорнии или в в скрытых штаб-квартирах компаний Google, Tesla, Apple и прочих.
В ходе статьи мы рассмотрим основные положения искусственного интеллекта и постараемся создать свою нейронную сеть на основе языка Python.
Искусственный интеллект
Ни для кого не секрет, что ИИ появился еще в середине прошлого столетия – в 1956 году. Тогда появилась сама концепция этой технологии, были описаны основные парадигмы и принципы. В те времена разработать ИИ не представлялось возможным, ведь тогдашние компьютеры были не мощнее современных калькуляторов, а, собственно, про какой ИИ может идти речь на калькуляторе?
Первый крупный прорыв состоялся в 1996 году. Тогда программа Deep Blue компании IBM обыграла чемпиона по шахматам Гарри Каспарова. Полноценным ИИ это сложно было назвать, ведь шахматы имеют конечное количество возможных ходов и программе необходимо было обладать знаниями обо всех возможных исходах, чтобы предсказать выигрышную стратегию для себя.

Следующий важный прорыв случился уже в 2016 году. Тогда программа AlphaGo компании Google DeepMind обыграла чемпиона мира по Го – Ли Седоля. Это стало важным событием, ведь в Го неограниченное или практически неограниченное количество возможных решений. Здесь в силу вступило машинное обучение, которое не оперировалось на всех возможных комбинациях игры, а оперировалось на основе своих собственных предположений, весов, которые подсказывали как стоит походить в разного рода ситуациях.
Это звучит как действительно настоящие компьютерные мозги, но насколько живи эти мозги? В статье мы еще подберемся к теме обучения нейронной сети, но пока лишь стоит сказать, что подобные программы основываются на достаточно простом для понимания принципе. В программу мы даем различные условия и говорим что при одном условии, будет выигрыш, а при другом — проигрыш. Обучив нейронку тысячами таких примеров она способна сама взвесить входные данные и понять к какому ответу они больше похожи — к выигрышному или наоборот.
Машинное обучение и глубокое обучение
Машинное обучение – это процесс обучения нейронной сети. Обучение, если говорить простыми словами, проходит за счёт указания нескольких вариантов одного решения, а затем нескольких вариантов другого. Далее нейронная система будет иметь некие весы для взвешивания новых задач и будет определять какое значение мы ей предлагаем.
Глубокое обучение – это подмножество машинного обучения. Оно является более дорогим и обучение проходит на гораздо большем массиве данных.
Получается следующая иерархия: есть нейронные сети, которые требуется обучить, выполнить машинное обучение или глубокое обучение. После их обучения мы получаем искусственный интеллект, что способен сам решать поставленные перед ним задачи.
Задача классификации
Теперь рассмотрим нейронную сеть на примере задачи классификации. Нейронные сети способны решать множество задач, мы же рассмотрим наиболее простую из них – задачу классификации. Суть задачи состоит в классификации объекта к определенной группе. Например, мы рисуем число 0, а нейронка должна понять что это за число. Другой пример, мы указываем характеристики автомобиля, а нейронка исходя из описания классифицирует машину и говорит её название.
В любой нейронке есть входные сигналы. Это те характеристики что мы с вами указываем, например, описание автомобиля. На основе этих данных нейронная сеть должна понять какой это автомобиль. Чтобы сделать решение она должна взвесить предоставленные данные и для этого используются, так называемые, весы. Это дополнительные числа, на которые в последствии будут умножены входные сигналы.

После умножения все данные суммируют, добавляется число корреляции и далее результат сравнивают с неким числом. Если итог более числа 0, то можно предположить, что машина, к примеру, Mercedes, а если менее 0, то это будет, например, BMW.
Мы рассмотрели работу лишь одного нейрона. Обычно для задач используется сеть нейронов, то есть объединение нескольких нейронов, где каждый из них решает какую-либо свою небольшую задачу.

Первый слой нейронов может решить несколько своих небольших задач и дать нам ответы. Далее на основе ответов формируется второй слой нейронов, скрытый слой, который также решает задачи и дает ответы. Таких слоев может быть множество и чем их больше, тем сложнее нейронная сеть. В конечном результате мы получаем множество взвешенных решений и на их основе спокойно можем вынести вердикт. В нашем примере нейронка могла бы сказать к какой марке относиться автомобиль.
Почем Python?
На самом деле, вы можете использовать любые языки для этой цели. Можно писать ИИ используя: JavaScript, Java, Go и так далее. Питон не гласно принят одним из лидеров этой сфере по причине своей распространенности, известности и огромного множества библиотек, что обладают набором встроенных математических функций для решения задач внутри нейронной сети.
Мы тоже будем использовать Питон, но знайте, что такое можно написать и без использования библиотек, а соответственно можно писать хоть на PHP, хоть на C#. Нет смысла писать математические функции самому по типу Сигмоида, функция получения случайного числа и тому подобных. По этой причине мы будем использовать Python и библиотеку numpy .
Разработка нейронной сети
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Код для реализации простой нейронной сети:
Изучение программирования
А вы хотите стать программистом и начать разрабатывать самостоятельно ИИ или хотя бы использовать уже готовые для своих собственных проектов? Предлагаем нашу программу обучения по языку Python . В ходе программы вы научитесь работать с языком, изучите построение мобильных проектов, научитесь создавать полноценные веб сайты на основе фреймворка Джанго, а также в курсе будет модуль по изучению нескольких готовых библиотек для искусственного интеллекта.
Источник
Нейронные сети на Python: как написать и обучить



Нейронные сети — это огромное множество алгоритмов в области машинного обучения. Из чего они состоят и как работают? Давайте попробуем в этом разобраться.
Нейронная сеть — это функциональная единица машинного или глубокого обучения. Она имитирует поведение человеческого мозга, поскольку основана на концепции биологических нейронных сетей.
Нейронные сети способны решать множество задач. В основном они состоят из таких компонентов:
- входной слой (получение и передача данных);
- скрытый слой (вычисление);
- выходной слой.
Чтобы реализовать нейросеть, необходимо понимать, как ведут себя нейроны. Нейрон одновременно принимает несколько входов, обрабатывает эти данные и выдает один выход.

Схематическое изображение нейронной сети
Проще говоря, нейронная сеть представляет собой блоки ввода и вывода, где каждое соединение имеет соответствующие веса (это сила связи нейронов; чем вес больше, тем один нейрон сильнее влияет на другой). Данные всех входов умножаются на веса:
Входы после взвешивания суммируются с прибавлением значения порога «c»:
Полученное значение пропускается через функцию активации (сигмоиду), которая преобразует входы в один выход:
z = ƒ(x*w 1 + y*w 2 + c)
Так выглядит сигмоида:
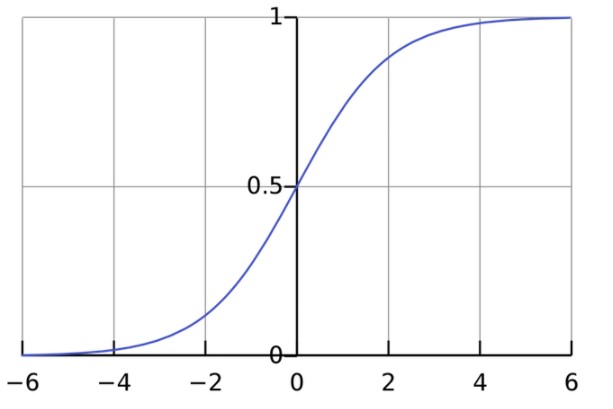
Интервал результатов сигмоиды — от 0 до 1. Отрицательные числа стремятся к нулю, а положительные — к единице.
Пусть нейрон имеет следующие значения: w = [0,1] c = 4
Входной слой: x = 2, y = 3.
((x*w 1 ) + (y*w 2 )) + c = 2*0 + 3*1 + 4 = 7
Как написать свой нейрон
Для написания кода нейрона будем использовать библиотеку Pytnon — NumPy .
Мы использовали значения из примера выше и видим, что результаты вычислений совпадают и равны 0.99.
Как собрать нейросеть из нейронов
Нейросеть состоит из множества соединенных между собой нейронов.
Пример несложной нейронной сети:
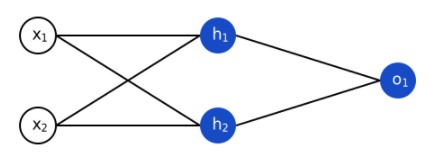
Простая нейронная сеть
- x 1 , x 2 — входной слой;
- h 1 , h 2 — скрытый слой с двумя нейронами;
- o 1 — выходной слой.
Внимание! Слоев в нейросети, так же как и нейронов, может быть любое количество.
Представим, что нейроны из графика выше имеют веса [0, 1]. Пороговое значение (b) у обоих нейронов равно 0 и они имеют идентичную сигмоиду.
При входных данных x=[2, 3] получим:
h 1 = h 2 = ƒ(w*x+b) = ƒ((0*2) + (1*3) +0) = ƒ(3) = 0.95
o 1 = ƒ(w*[h 1 , h 2 ] +b) = ƒ((0*h 1 ) + (1*h 2 ) +0) = ƒ(0.95) = 0.72
Входные данные по нейронам передаются до тех пор, пока не получатся выходные значения.
Код нейросети
Видим, что нейронная сеть создана, выходное значение равно 0.72.
Обучение нейронной сети
Обучение нейросети — это подбор весов, которые соответствуют всем входам для решения поставленных задач.
Класс нейронной сети:
Каждый этап процесса обучения состоит из:
- прямого распространения (прогнозируемый выход);
- обратного распространения (обновление весов и смещений).
Дана двуслойная нейросеть:
ŷ = σ(w 2 σ(w 1 x + b 1 ) + b 2 )
В данном случае на выход ŷ влияют только две переменные — w (веса) и b (смещение).
Настройку весов и смещений из данных входа или процесс обучения нейросети можно изобразить так:

Процесс обучения нейросети
Прямое распространение
Как видно, формула прямого распространения представляет собой несложное вычисление:
ŷ = σ(w 2 σ(w 1 x + b 1 ) + b 2 )
Далее необходимо добавить в код функцию прямого распространения. Предположим, что смещения в этом случае будут равны 0.
Чтобы вычислить ошибку прогноза, необходимо использовать функцию потери. В примере уместно воспользоваться формулой суммы квадратов ошибок — средним значением между прогнозируемым и фактическим результатами:
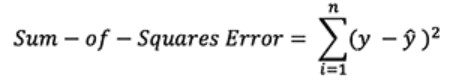
Формула суммы квадратов ошибок
Обратное распространение
Обратное распространение позволяет измерить производные в обратном порядке — от конца к началу, и скорректировать веса и смещения. Для этого необходимо узнать производную функции потери — тангенс угла наклона.
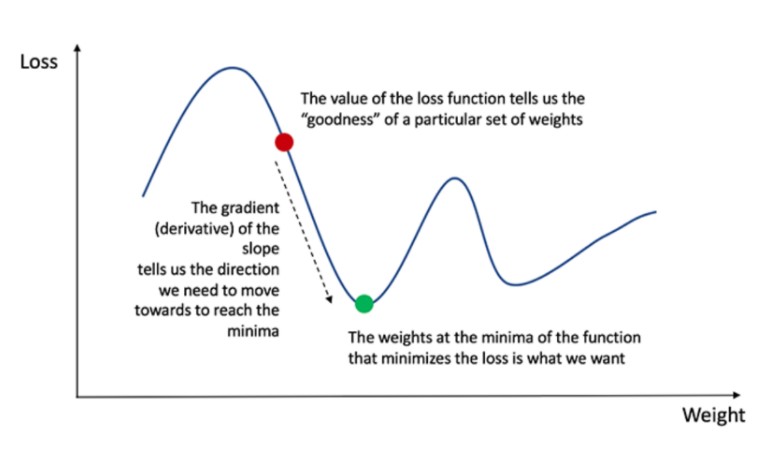
Тангенс угла наклона — производная функции потери
Производная функции по отношению к весам и смещениям позволяет узнать градиентный спуск.
Производная функции потери не содержит весов и смещений, для ее вычисления необходимо добавить правило цепи:
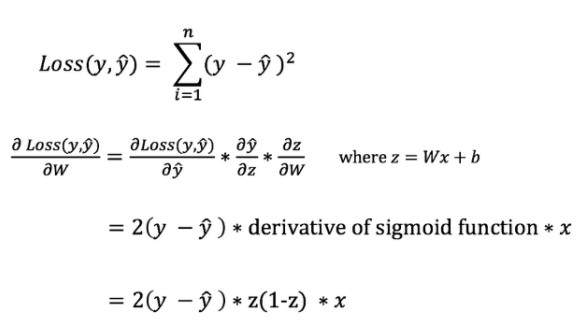
Благодаря этому правилу можно регулировать веса.
Добавляем в код Python функцию обратного распространения:
Нейронные сети базируются на определенных алгоритмах и математических функциях. Сначала может казаться, что разобраться в них довольно сложно. Но существуют готовые библиотеки машинного обучения для построения и тренировки нейросетей, позволяющие не углубляться в их устройство.
Источник
Создание простой нейронной сети на Python

Feb 26 · 8 min read
![]()
В течение последних десятилетий машинное обучение оказало огромное влияние на весь мир, и его популярность только набирает обороты. Все больше людей увлекается подотраслями этой науки, например нейронными сетями, которые разрабатываются по принципам функционирования человеческого мозга. В этой статье мы разберем код Python для простой нейронной сети, классифицирующей векторы 1х3, где первым элементом является 10.
Шаг 1: импорт NumPy, Scikit-learn и Matplotlib
Для этого проекта мы используем три пакета. NumPy будет служить для создания векторов и матриц, а также математических операций. Scikit-learn возьмет на себя обязанность по масштабированию данных, а Matpotlib предоставит график изменения показателей ошибки в процессе обучения сети.
Шаг 2: создание обучающей и контрольной выборок
Нейронны е сети отлично справляются с изучением тенденций как в больших, так и в малых датасетах. Тем не менее специалисты по данным должны иметь в виду опасность возможного переобучения, которое чаще встречается в проектах с небольшими наборами данных. Переобучение происходит, когда алгоритм слишком долго обучается на датасете, в результате чего модель просто запоминает представленные данные, давая хорошие результаты конкретно на используемой обучающей выборке. При этом она существенно хуже обобщается на новые данные, а ведь именно это нам от нее и нужно.
Чтобы гарантировать оценку модели с позиции ее возможности прогнозировать именно новые точки данных, принято разделять датасеты на обучающую и контрольную выборки (а иногда еще и на тестовую).
В этой простой нейронной сети мы будем классифицировать вектора 1х3 с 10 в качестве первого элемента. Вход и выход обучающей и контрольной выборок создаются с помощью функции NumPy array , а input_pred реализуется для тестирования функции prediction , которую мы определим позже. И обучающая, и контрольная выборки состоят из шести образцов с тремя признаками каждый. И поскольку выход определен заранее, этот пример можно считать обучением с учителем.
Шаг 3: масштабирование данных
Многие модели МО не способны понимать различия между, например единицами измерения, и будут, естественно, придавать большие веса признакам с большими величинами. Это может нарушить способность алгоритма правильно прогнозировать новые точки данных. Более того, обучение моделей МО на признаках с высокими величинами будет медленнее, чем нужно, по крайней мере при использовании градиентного спуска. Причина в том, что градиентный спуск сходится к искомой точке быстрее, когда значения находятся приблизительно в одном диапазоне.
В наших обучающей и контрольной выборках значения расположены в относительно небольшом диапазоне, поэтому можно и не применять масштабирование признаков. Однако данная процедура все-таки включена, чтобы вы могли использовать собственные числа без особых изменений кода. Масштабирование признаков реализуется в Python очень легко, в чем помогает пакет Scikit-learn и его класс MinMaxScaler . Просто создайте объект MinMaxScaler и используйте функцию fit_transform с исходными данными в качестве входа. В результате эта функция вернет те же данные уже в масштабированном виде. В названном пакете есть и другие функции масштабирования, которые стоит попробовать.
Шаг 4: Создание класса нейронной сети
Один из простейших способов познакомиться со всеми элементами нейронной сети — создать соответствующий класс. Он должен включать все переменные и функции, которые потребуются для должной работы нейронной сети.
Шаг 4.1: создание функции инициализации
Функция _init_ вызывается при создании класса, что позволяет правильно инициализировать его переменные.
Источник